
Hola de nuevo!
Recientemente se celebró la tercera edición de AsturCON en la que tuve el placer de participar y debutar por primera vez. En esta ocasión mi participación se basó en una continuación del taller «Vishing: Todo empieza con un Sí».

AsturCON es el principal congreso de ciberseguridad que se celebra en Asturias y ya van por su tercera edición. Tras vivirlo de primera mano, se les ve con muchísima energía, ganas de hacer las cosas bien de base y estoy seguro que seguirá al pie del cañón el próximo año. Desde aquí aprovecho para agradecer el trato y hospitalidad recibida, así como el esfuerzo que lleva realizar un evento de estas características.

Además, como en todos los congresos se da la oportunidad desde conocer nuevas personas hasta ver, charlar y obviamente, tomar unas buenas cervezas con antiguos amigos o compañeros del sector. Adicionalmente, le metes el extra de ser en Asturias incorporando una botella de sidra y un cachopo al plato xd
Tras esta mini-intro vamos allá a lo que es el asunto del post. Antes de comenzar, os recomiendo echar un vistazo al primer paso sobre el taller que podéis encontrar aquí, en donde se resumió las diferentes parte de una campaña de vishing, el OSINT sobre la empresa objetivo, los hitos a medir, entre otras cosas.
En esta ocasión, se va a hacer zoom sobre la clonación de voz dado que el servicio del que hice uso, también ha metido nuevas actualizaciones realmente potentes.
Uno de los principales factores que, desde mi punto de vista, ha afectado a la efectividad del vishing es la evolución de la IA en relación a la clonación de voz, o hasta incluso, como veremos más adelante, mantener una conversación como si fuera un humano.
De la IA’s que he testeado la que más me gusta, y también alcanzable a nivel económico es ElevenLabs. Elevenlabs no me paga por hacer publicidad ni me ha dado una licencia gratuita, tan sólo por puntualizar xd Tiene diferentes precios en función del plan que mejor se adapte a lo que busques, desde gratis hasta lo más top:
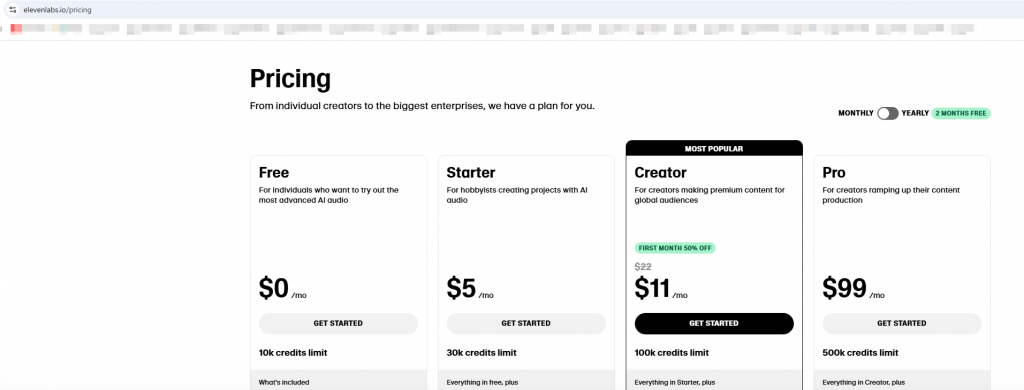
Obviamente cada una tiene sus limitaciones o acceso a funcionalidades, así como el número de créditos. En mi caso, utilizo el plan Creator, que es la que he utilizado para mostraros lo que vais a leer a continuación.
Una vez se pasa por caja y tras autenticarse, se puede encontrar el siguiente panel:
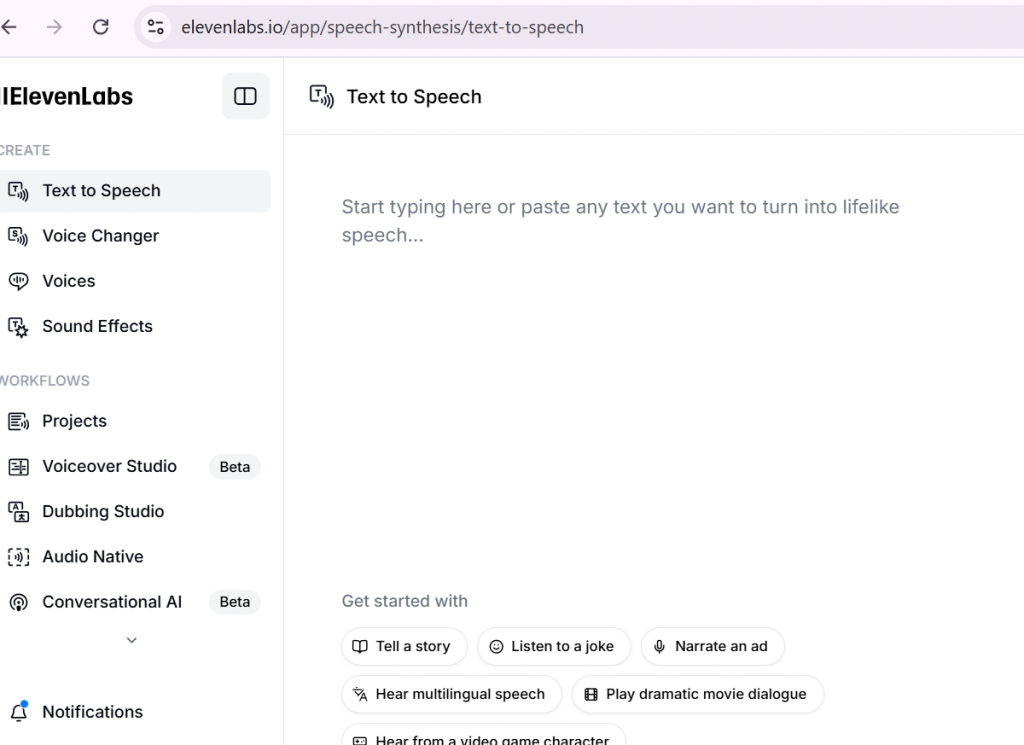
La primera funcionalidad es prácticamente auto-explicativa, pasar de texto a voz.
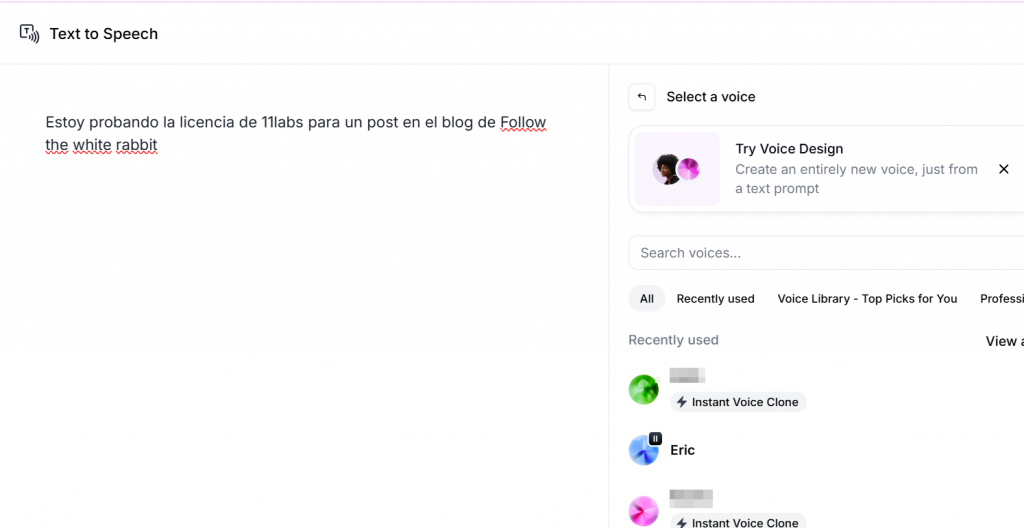
Tras añadir el texto que se desee aparece en la parte derecha la selección de las voces, bien de las librerias de la comunidad o también usar alguna voz clonada. En este caso, aparecen dos bajo la denominación «Instant voice clone» y luego aparece Eric que es una voz de la comunidad.
Dentro de las voces seleccionables de la comunidad se puede filtrar por idioma, edad, tono de voz, si es para mantener conversación o narración,…
Una vez seleccionada la voz, se encuentran las siguientes opciones (estabilidad, similitud y estilo de exageración) modificable para adaptar el speech lo mejor posible.
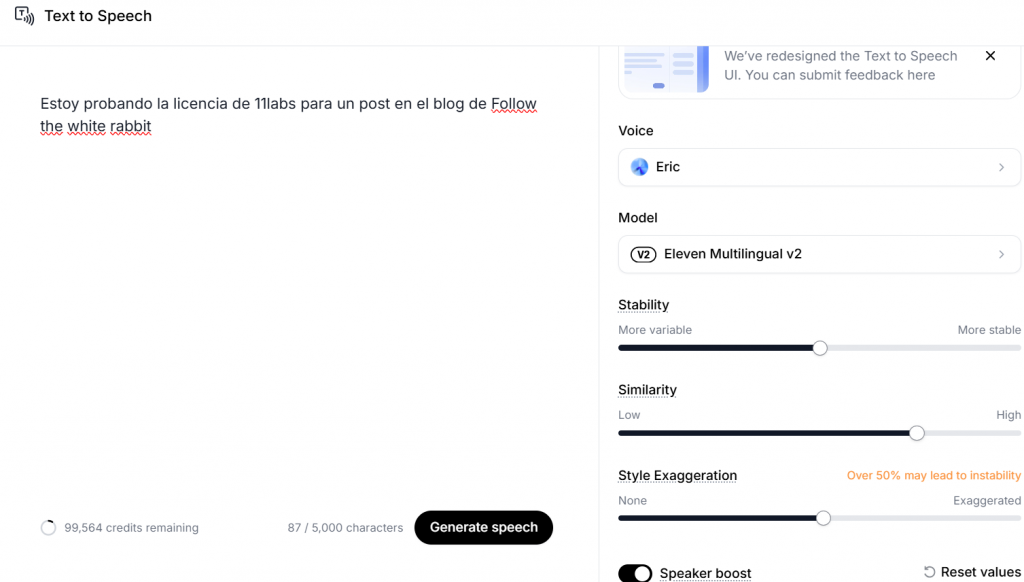
Cuidado con la opción de estilo de exageración que si supera el 50% puede ser inestable. Como consejo, citar que todas las voces son diferentes y no vale una misma configuración para todas, sino que hay que ir tirando prueba y error hasta ajustarlas. Tras generar un speech la aplicación permite dos regeneraciones gratuitas para ajustar el resultado.
Ni que decir tiene que en el caso de voz clonada importada, cuando más muestras se tengan mejores resultados 🙂
A continuación, se sube un ejemplo de audio con la voz del citado Eric:
Volviendo al menú, se encuentra «Voice Changer». Como su nombre indica, sirve para cambiar el registro de voz.
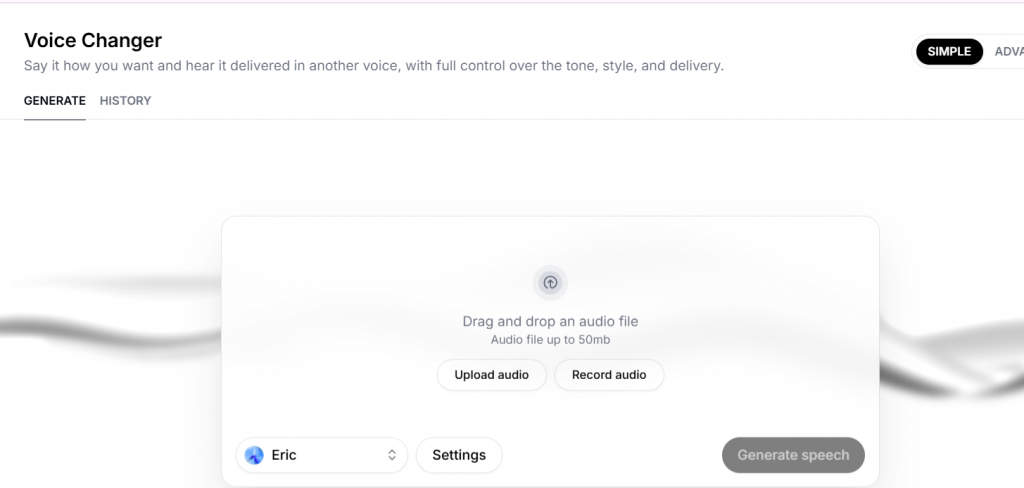
¿Para qué sirve esto? Por ejemplo, para adaptar la voz a un idioma, género o acento. Tras subir el audio o grabarlo en vivo, se puede cambiar a otra voz.
Otra funcionalidad interesante es la llamada como «Sounds Effects». Se trata de añadir «ruido» de fondo. ¿Para qué puede servir? Para darle contexto a la llamada, ruido de fondo de un restaurante, de un contact center o un bebe llorando.
En este caso, se selecciona generar el ruido de contact center y aparecen estas opciones:
Se añaden unos ejemplos:
De cara a esto se recomienda ver este video donde se usa un sonido de fondo para que se entienda con un ejemplo su uso:
Hay opción realmente interesar que es «Voice Isolator», que a través de su nombre se deduce su uso. Permite aislar la voz de un audio eliminando los ruidos de fondo, tal que permite obtener una muestra de voz limpia.
Nuevamente alguien se podría preguntar: ¿Para qué? Por ejemplo, para un audio que se haya podido obtener y se desea clonar pero tiene ruido de fondo (de ascensor, de música,…) tal que al clonarla el resultado no sea el deseado. Una vez obtenido la voz ya se puede volver a los apartados anteriores.
Finalmente, la funcionalidad más top para mí, Conversational AI, mantener una conversación con la IA:
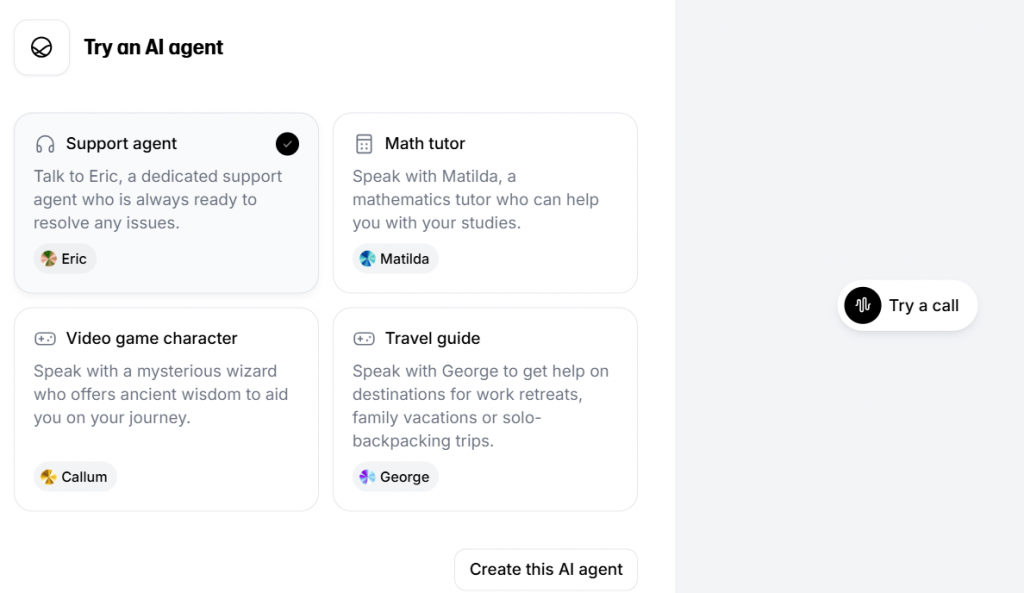
Ya vienen una serie de agentes creadas como el típico agente de soporte o un guía turístico, bien un profesor de matemáticas o hasta un personaje de un videojuego.
Adicionalmente, es posible crear un agente nueva de IA. En este caso, dado el contexto del post se ha partido del agente de soporte y se ha enseñado a convertirse en un visher. A continuación, se detallan los siguientes apartados para configurar:
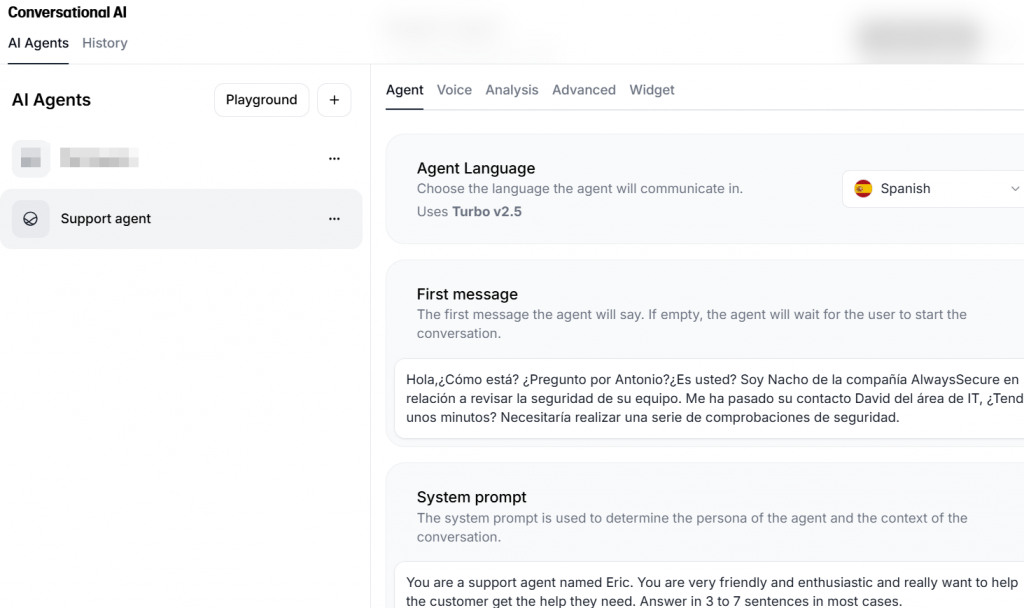
En esta primera pestaña, se puede configurar el idioma, el agente del contexto y cómo se empezar la conversación. En el caso de dejarlo vacío, la IA estará escuchando y se adaptará según cómo el usuario comienza la conversación.
Además, se encuentra la base de conocimiento:
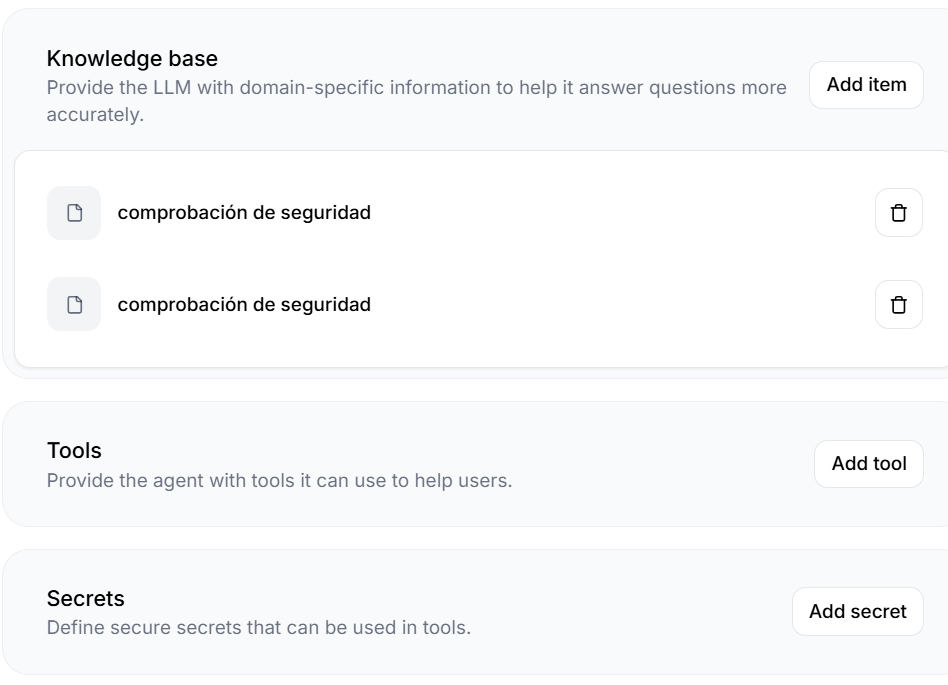
En este apartado se puede dar directrices para que siga la IA en la conversación. En este caso, se añadieron estas preguntas:

Además, se puede configurar el uso de herramientas para enviar peticiones a un servidor del propio usuario de información extraida por el agente, así como la configuración en el apartado de secretos, que se deduce que es una clave, secret_id o similar para autenticarse:
En la segunda pestaña, se puede seleccionar la voz, así como configurar los parámetros anteriormente comentados (estabilidad, similitud,..) así como el periodo de latencia.
La tercera pestaña se utiliza para entrenar a la IA en función del histórico, indicando el criterio de evaluación, así como la recolección de datos:
La cuarta pestaña contiene las opciones avanzadas:
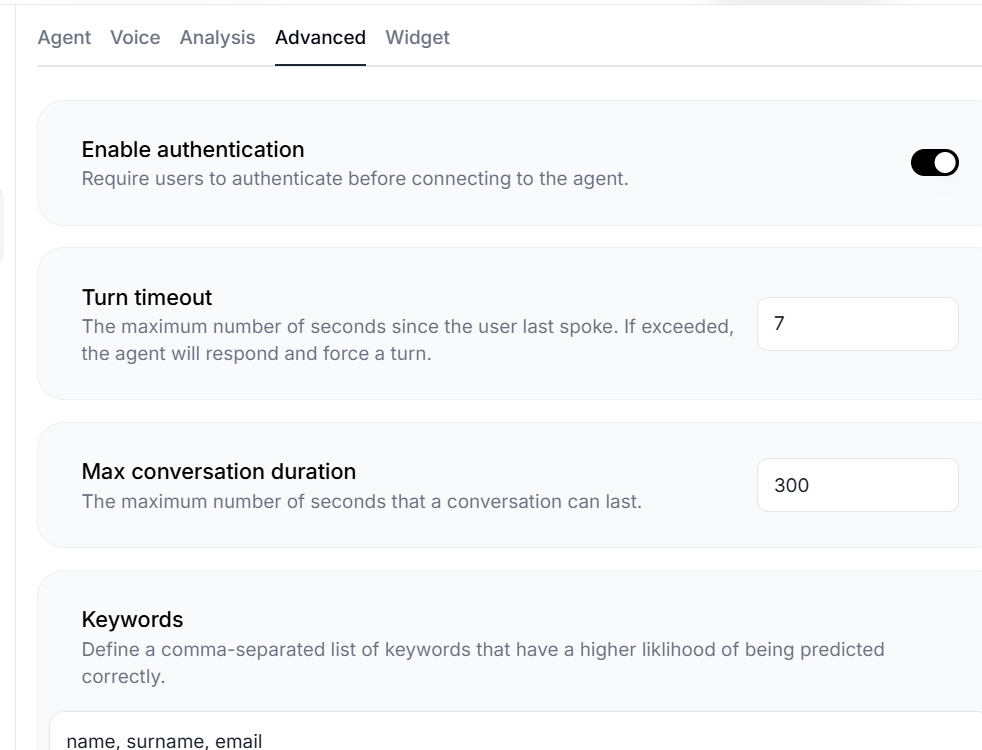
Desde requerir la autenticación de los usuarios (acordados de las preguntas de validación :)), la duración de la llamada o incorporar keywords.
Finalmente, se deje un ejemplo de uso de la IA mediante un fragmento de la conversación que tuve con ella simulando un vishing donde yo era la víctima y la IA el visher.
Como se puede observar la IA incluso se calla cuando se le interrumpe y sabe buscar respuestas ante respuestas no esperadas. Cuando más se la entrena, mejor sabe adaptarse.
Cuando vi esta funcionalidad me quede flipando y estuve cacharreando un buen par de horas 😀
La slides que use las podéis encontrar en mi github.
El objetivo del post es dar una referencia o apoyo para realizar campañas de vishing en proyectos de ciberseguridad, así como una manera para mejorar la prevención y respuesta. El autor ni el blog se hace responsable de su uso para otros fines diferentes a la formación.
Nos vemos en el siguiente post!
Saludos.
N4xh4ck5
La mejor defensa es un buen ataque