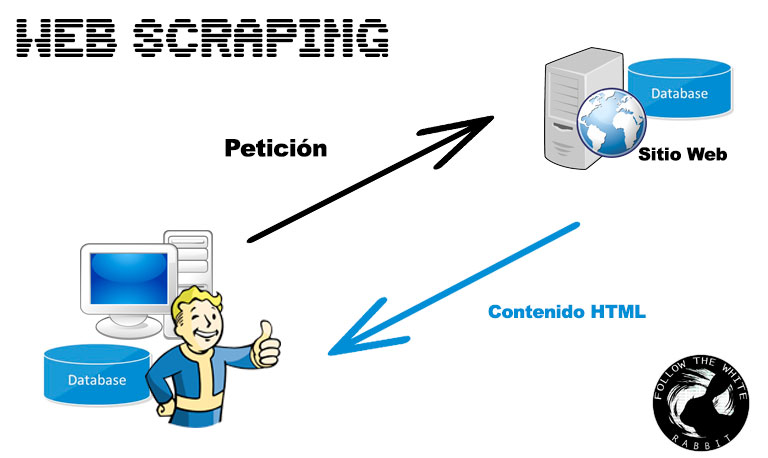
¿Qué sucede cuando queremos almacenar o analizar mucha información de un sitio web de una forma organizada y en el menor tiempo posible?
Web Scraping es la técnica que permite transformar la información pública desestructurada de una página web (HTML) en información estructurada para su posterior almacenamiento y análisis.
Las aplicaciones de esta técnica no tienen límite, desde almacenar el precio de un determinado producto en distintos establecimientos para compararlos, detectar cambios en un sitio web o crear inteligencia hasta generar una base de datos a través del contenido de un sitio web para añadir funcionalidades que la web no tiene.
Aviso legal: Ciertos sitios web prohíben el empleo de este tipo de técnicas en las Condiciones de uso, consultar siempre con el administrador del sitio web antes de ejecutarla.
A continuación desarrollaremos una pequeña Prueba de concepto de lo que esta técnica nos permite hacer. Para ello hemos seleccionado un sitio web que hace pública información de gran interés sobre empresas españolas. En concreto muestra la siguiente información de más de 28.000 sociedades.
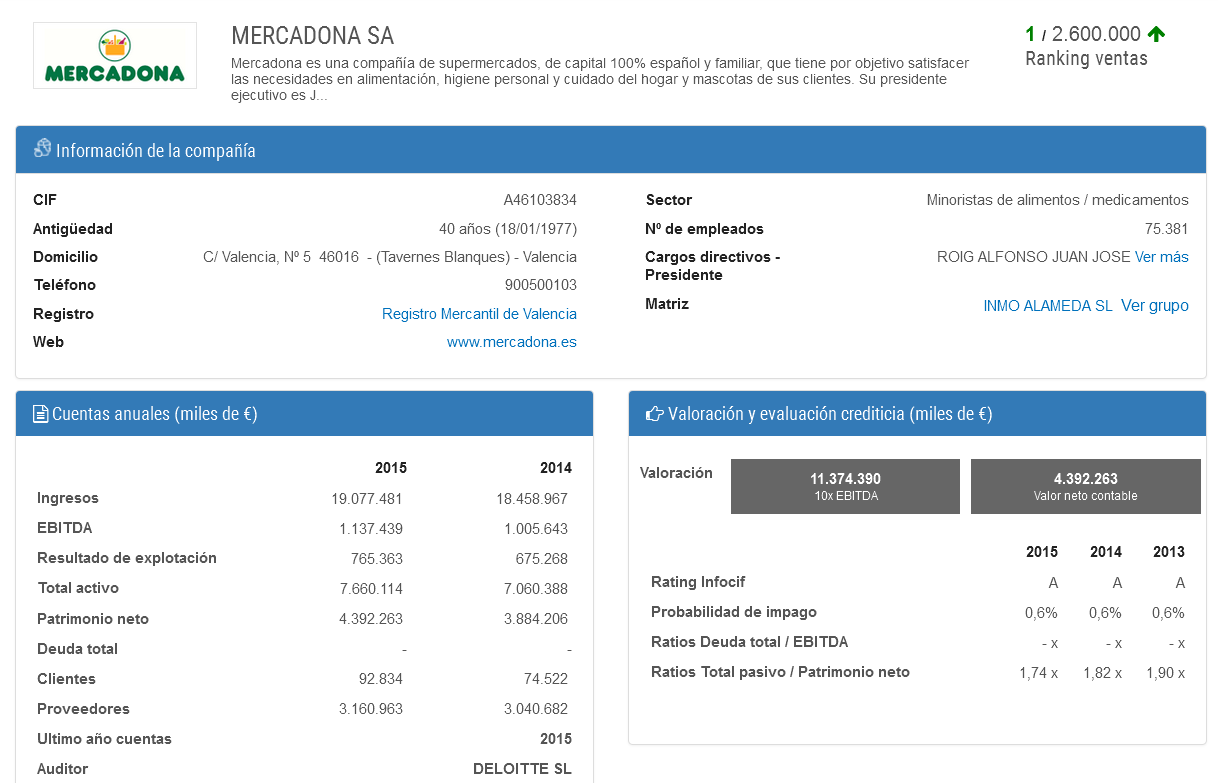
Para acceder la información tendremos que superar dos fases:
- El sitio web crea una página por cada empresa, por lo que deberemos almacenar los enlaces de dichas páginas para la posterior extracción.


- Parsear el código HTML obtenido para localizar y almacenar unicamente la información que nos interesa.
Nuestro objetivo es almacenar toda la información de interés en una base de datos de forma automatizada. Para ello y con la ayuda de mi compañero Andrés hemos desarrollado un pequeño script en PHP el cual podéis descargar desde aquí.
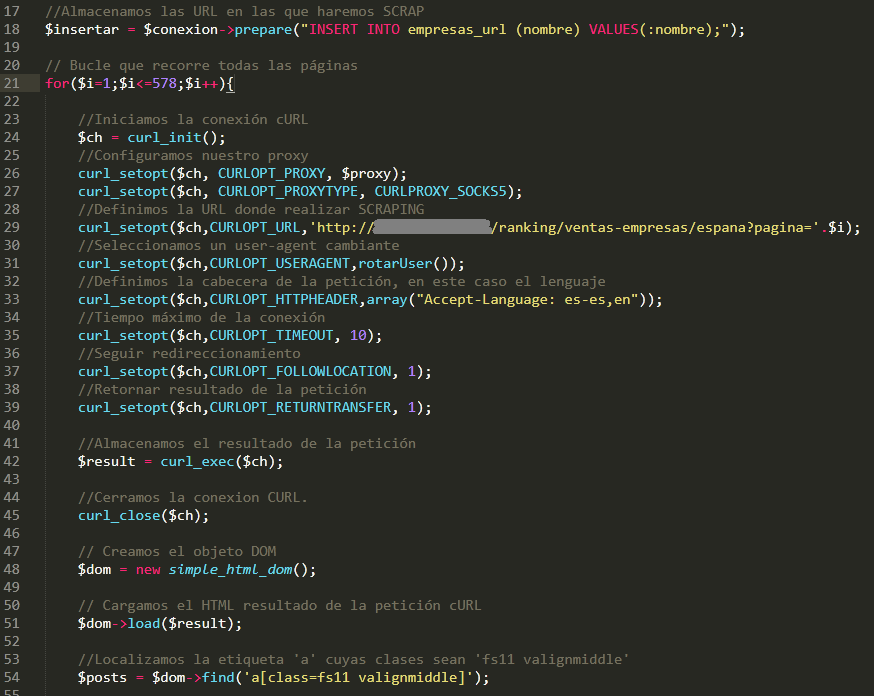
Basicamente enviamos una petición cURL por cada página para capturar la URL de la empresa, para ello localizamos el enlace empleando DOM. Si lo deseamos podemos hacer las peticiones a través de un proxy como TOR y generar las peticiones modificando el User Agent.
Una vez tengamos todas las URL almacenadas lanzamos el segundo script que nuevamente filtra el HTML obteniendo solo la información que nos interesa. Utilizamos la función find de simple_html_dom.php para localizar las etiquetas HTML que contienen los datos a almacenar.
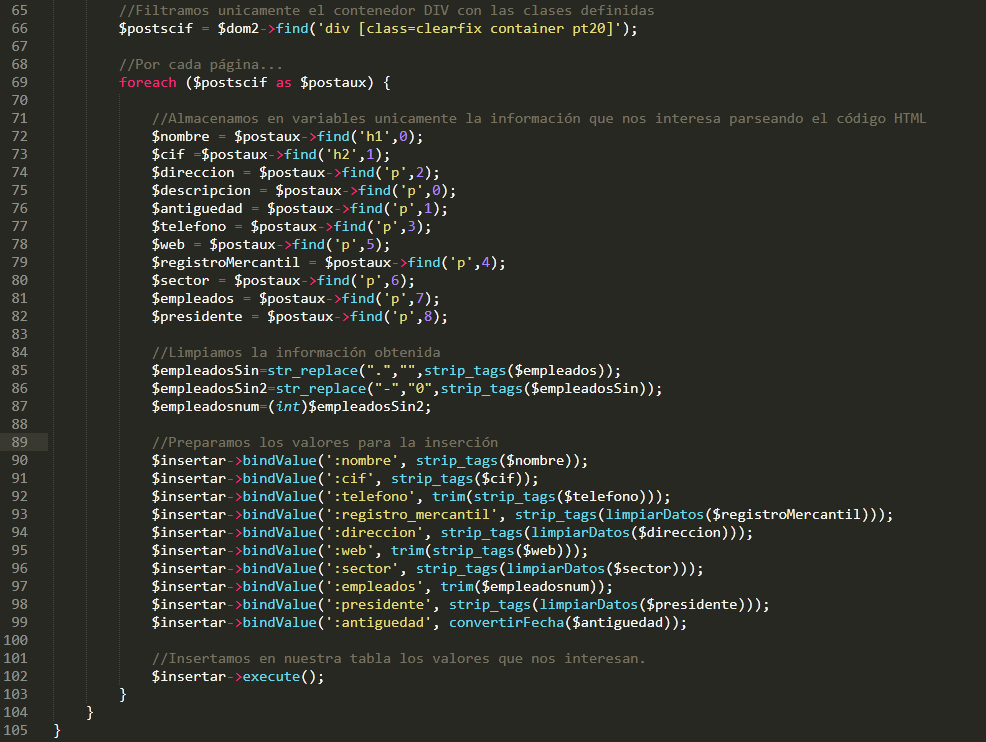
De esta forma conseguimos filtrar, organizar y almacenar toda la información de una forma automatizada.

Como podéis ver es realmente sencillo y las posibilidades del Scraping van tan lejos como pueda ir nuestra imaginación.
Hasta la próxima 😉
Metalex
7 comentarios en «Web Scraping: Almacenando Información»
Hola,
Se podria probar el script con tor?
Independientemente de si esta programado en php, python.. etc
Gracias
Buenas,
Claro, sin problemas. En la versión php de Github encontrarás el código lanzado a través de Tor, unicamente lanzas peticiones HTTP.
Un saludo,
hola
queria probar este script pero me da problemas al ejecutarlo..
php scrapregistros.php
PHP Parse error: syntax error, unexpected ‘curl_setopt’ (T_STRING) in /home/7even/Desktop/Web-Scraping-master/scrapregistros.php on line 42
la linea 42 que dice es esta:
//Seleccionamos un user-agent cambiante
curl_setopt($ch2,CURLOPT_USERAGENT,);
he buscado info y parece que tengo que configurar el user agent ( pero cada uno dice una cosa XD)
http://www.forosdelweb.com/f18/problema-curl-abrir-web-1123737/
en user agent no habria que poner algo parecido a lo que dicen en foros del web(?)
‘Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.0.3705; .NET CLR 1.1.4322)’);
muchas gracias
Muy buenas,
Al emplear la opción CURLOPT_USERAGENT estamos definiendo el User-Agent por el cual enviaremos la petición al servidor, el código especifica lo siguiente:
curl_setopt($ch2,CURLOPT_USERAGENT,rotarUser());
La función rotarUser se define más abajo y genera un user agent aleatorio si te da error prueba a sustituir la función por un user agent estático.
Un saludo,
Creo que es más sencillo directamente usar un plugin como el genial: https://chrome.google.com/webstore/detail/web-scraper/jnhgnonknehpejjnehehllkliplmbmhn?utm_source=chrome-app-launcher-info-dialog
Buenas,
Al ser un desarrollo propio es posible implementar dicho código en otras aplicaciones, concretamente esta surgió por la necesidad de añadir funcionalidades a otra aplicación, el plugin de Chrome es muy util si unicamente quieres descargar el contenido en un CSV pero está limitado, siempre tendrás más poder de acción y flexibilidad al poder modificar el código en función de tus necesidades.
Un saludo,