
Burp Suite I: La Navaja Suiza del Pentester
Burp Suite II: Construyendo un objetivo, Sitemap & Spider
Buenos días Hackers!
Tras la primera entrada de la serie Burp Suite, donde vimos la instalación y configuración tanto de la herramienta como del proxy y certificado digital , hoy por fin, y después de unas cuantas semanas de parón os traigo la segunda entrega.
En este caso, seguiremos aprendiendo algunas de las funcionalidades más importantes de Burp Suite desde el punto de vista de una auditoria de seguridad.
Contenido:
- Construyendo un Objetivo – Target Scope
- Estructura de una Web – Sitemap
- Crawler Automatizado – Spider
Construyendo un Objetivo – Target Scope
Como vimos en la entrada anterior, desde la pestaña Target podremos fijar el alcance (Scope) y construir un Sitemap a partir de él. En este caso, supondremos que se está realizando una auditoria a la web https://www.fwhibbit.es, por tanto nuestro Scope será únicamente esta web.
En esta pestaña, se mostrarán todos los dominios a los que vayamos accediendo durante la auditoria. Como podemos ver en la siguiente imagen, se observan accesos a páginas como facebook o google que se realizan de manera automática por gran parte de las webs que existen en la actualidad (ya sea a través de anuncios, APIs, etc).
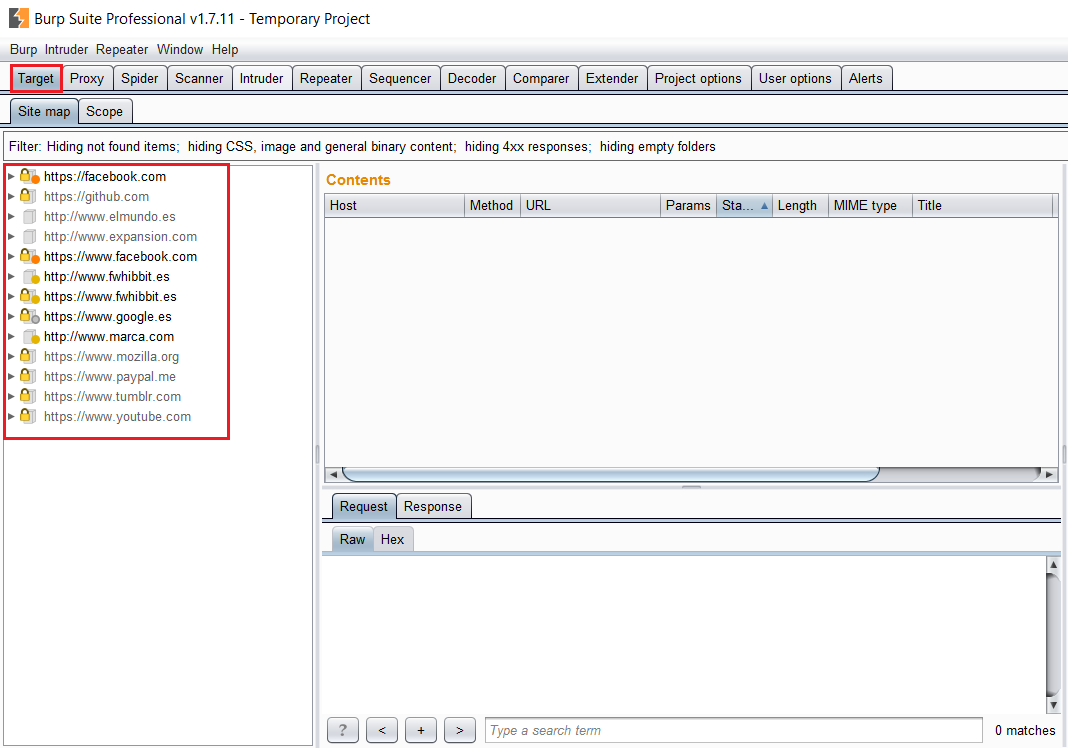
Dado que solo nos interesa analizar la web de fwhibbit, buscamos el dominio en la lista de Targets -> clic derecho -> «Add to Scope»
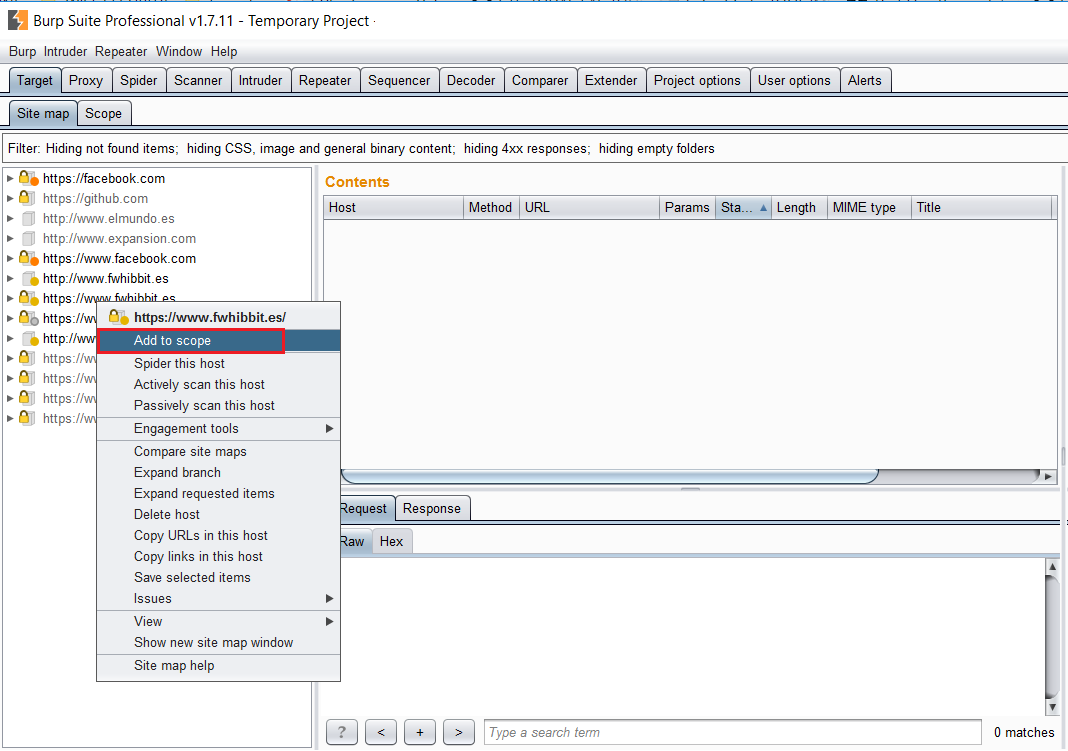
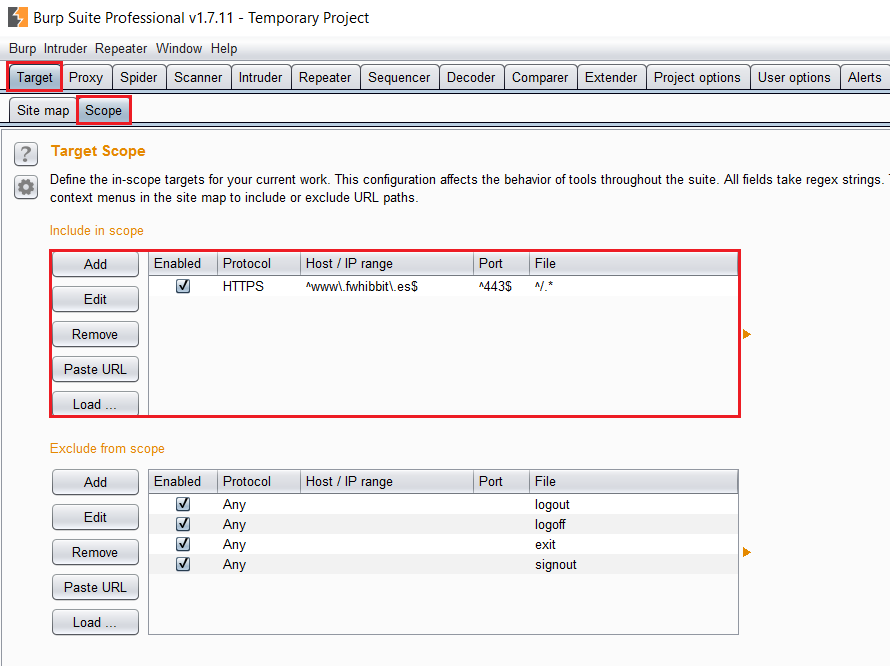
Si vamos a la subpestaña Scope, comprobamos que se ha añadido un nuevo dominio a la lista de Target Scope. Cabe destacar que estas reglas pueden ser modificadas o añadidas manualmente, especificando un rango concreto de dominios/subdominios mediante expresiones regulares.
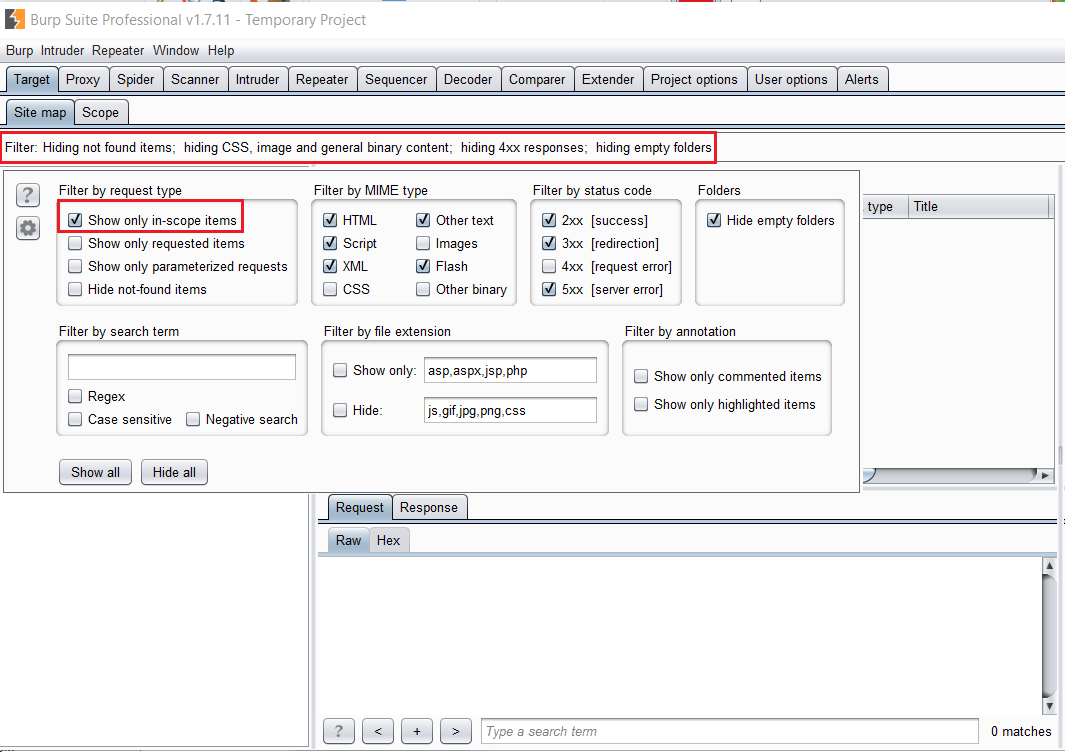
Ahora solo queda modificar el filtro de la pestaña Target, indicándole que muestre únicamente los dominios incluidos en el Scope. Esto nos permitirá analizar el objetivo que nos interesa, inspeccionando e identificando el listado de links del sitio web.
Estructura de una Web – Sitemap
El Sitemap es un fichero en formato XML que permite realizar una correcta indexación de un sitio web en los principales motores de búsqueda.
En la subpestaña Sitemap, podremos obtener una visión más detallada acerca de la estructura de la web conforme vamos avanzando, identificando algunos directorios o recursos ocultos, localizando posibles fugas de información en los recursos, así como dominios mal configurados y errores no controlados.
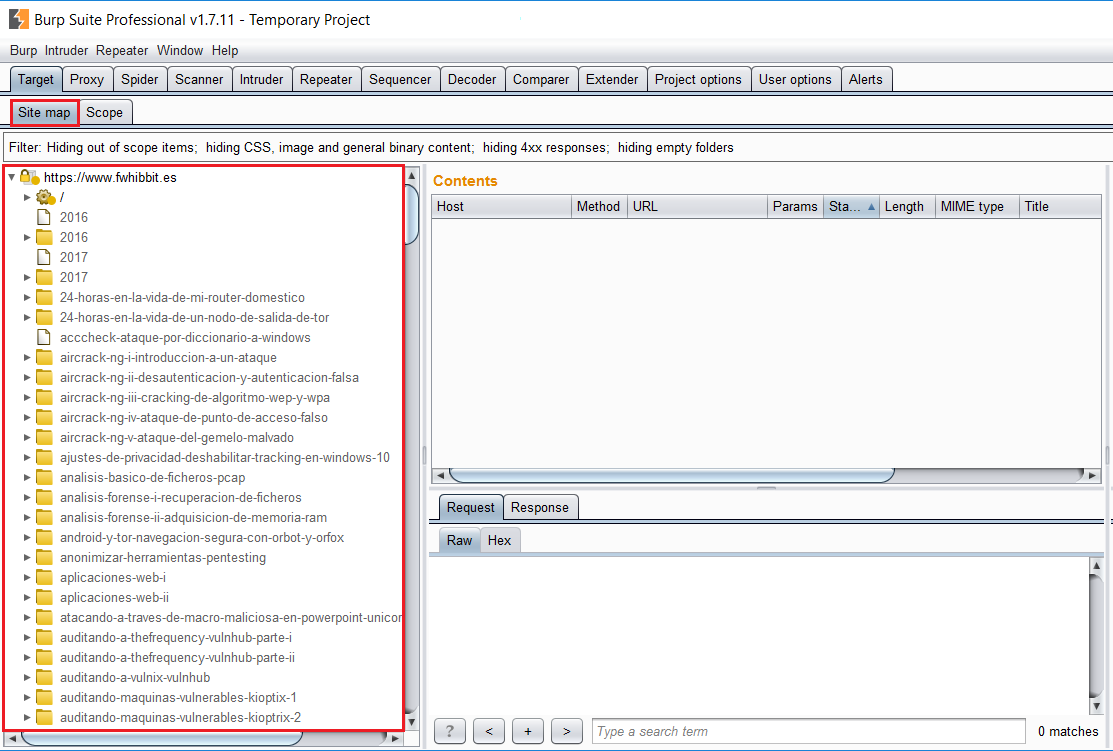
Si observamos la captura anterior, vemos como se han identificado algunas de las entradas del blog fwhibbit.es, simplemente accediendo a su página principal. Como habréis observado, únicamente aparece el dominio que hemos incluido previamente en el Scope 😉
Crawler Automatizado – Spider
Como no podía ser de otra manera, Burp Suite incluye un Spider (crawler), que permite inspeccionar de forma metódica y automatizada los directorios, ficheros (html, txt, php, js), vínculos y enlaces del sitio web que estamos analizando.
Es una funcionalidad similar a la construcción del Sitemap, solo que en este caso, se realiza de manera automática. Esto puede llegar a ser un problema si la web está mal diseñada, dado que se realizan peticiones de manera descontrolada sin atender a la lógica.
Hay que tener mucho cuidado cuando utilicemos el Spider de Burp Suite, ya que el Spider también se encarga de rellenar los formularios (inputs) que se va encontrando y he visto casos en los que el Spider se ha cargado una web, eliminado todos los usuarios del sistema o incluso modificado información de los clientes (usuarios, emails, contraseñas, etc).
Para lanzar el Spider, bastará con hacer clic derecho sobre el dominio fwhibbit.es y pulsar en «Spider this host».
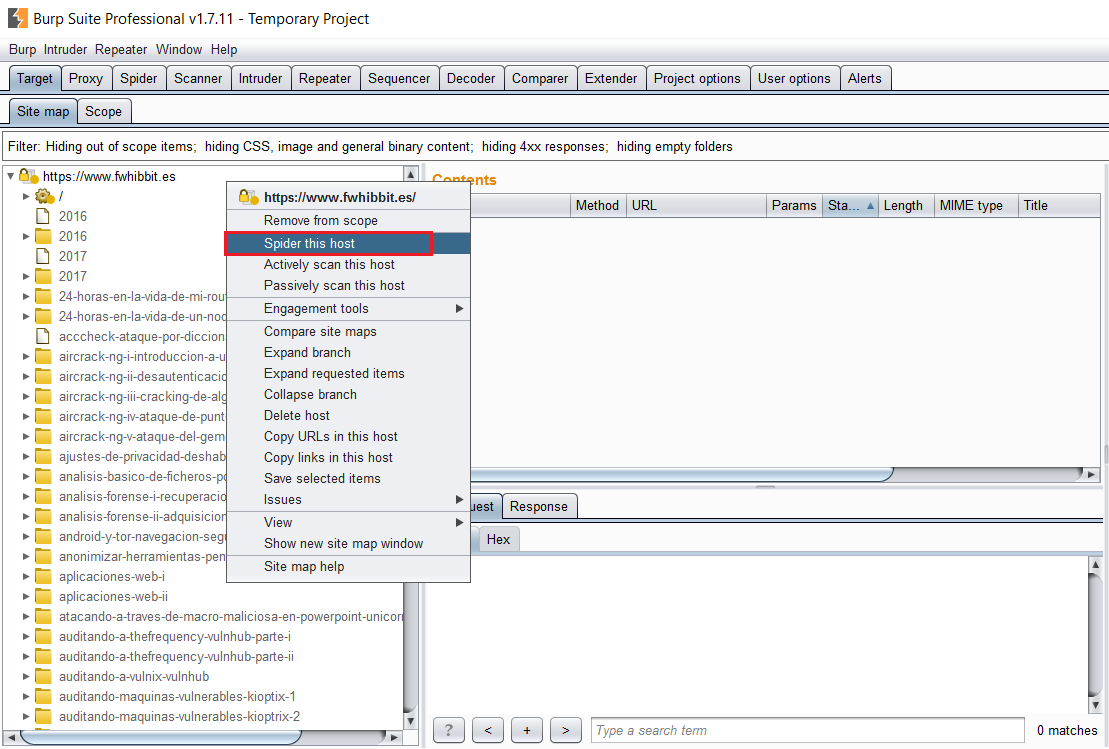
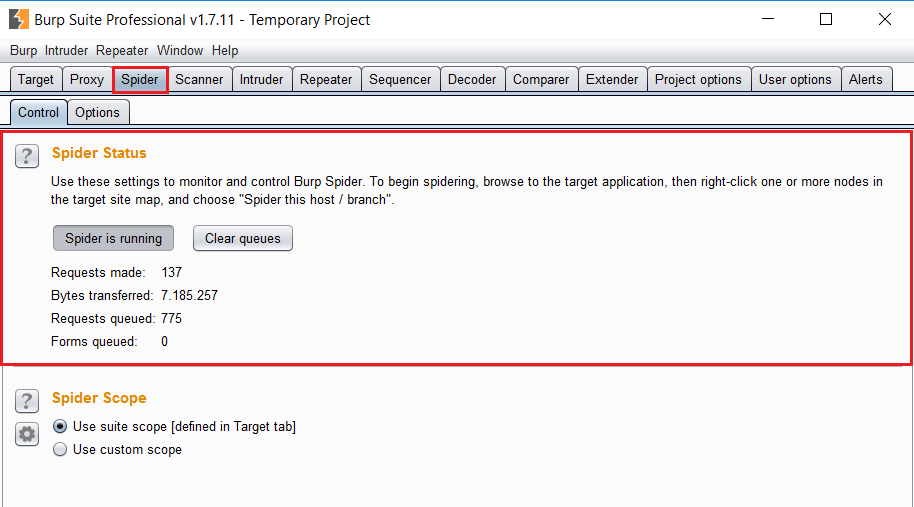
Si navegamos hasta la pestaña Spider, en la subpestaña control, podemos ir viendo el número de peticiones que se va realizando. Si queremos pausar el crawling, simplemente pulsaremos sobre el botón «Spider is Running».
En la subpestaña Options, configuraremos las opciones del Spider, y determinaremos, entre otras cosas, los datos y credenciales que van a ser utilizados por el crawler en los formularios del sitio web.
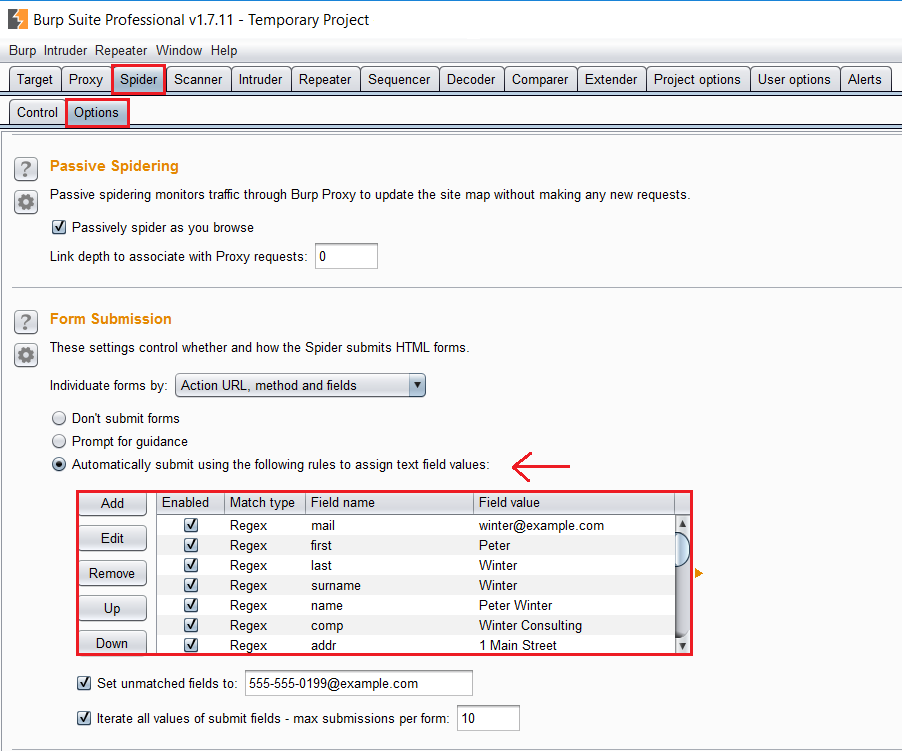
Esto resulta de gran utilidad a la hora de localizar nuevos recursos y sobre todo encontrar posibles vulnerabilidades en nuestra web (p.e Cross-Site Request Forgery, como veremos en futuras entradas).
A continuación tenemos otro ejemplo, donde el Spider ha localizado un archivo que no habíamos localizado en la búsqueda manual (wp-comments-post.php) y vemos que el propio crawler se ha encargado de rellenar el formulario por nosotros (que majo oye!).
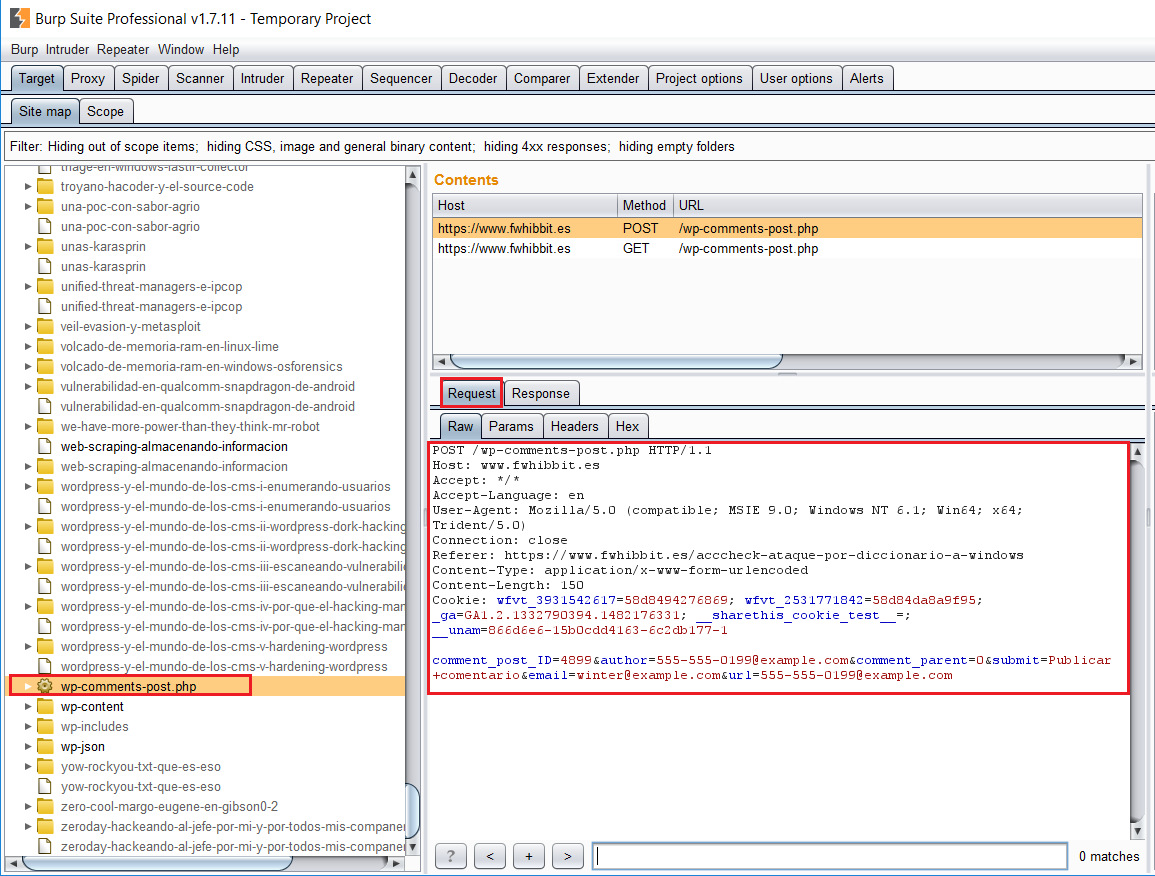
Y con esto acaba la entrada de hoy, espero que os haya gustado!! Quiero recalcar que estas primeras entradas serán bastante básicas y a modo de introducción, ya que es importante afianzar los conceptos antes de ponernos a hacer maldades, digo…practicar en entornos controlados! 😀
Un saludo y que tengáis un buen inicio de semana!!
Diego Jurado (@djurado9)
2 comentarios en «Burp Suite II: Construyendo un objetivo, Sitemap & Spider»
Brutal!! Saber manejar burp es un puntazo!!