Hola secuaces:
En la entrada anterior, vimos cómo crear un caso y generar unos índices, (extraer las strings), con OSForensics en Windows. En esta ocasión, y con el fin de ver que cada herramienta trabaja de forma distinta, según la plataforma a usar, vamos a crear un caso con Autopsy, (un Framework Forense por excelencia), y a extraer sus correspondientes strings.
No voy a entrar en profundidad porque daría para una larga serie de entradas. Pero sí voy a decir que existen opciones que no son explicadas de forma habitual, (las veréis enseguida). Lo que quiero es comparar esta forma de trabajar con la anterior.
Autopsy es una plataforma forense digital y una interfaz gráfica para The Sleuth Kit y otras herramientas forenses digitales. En Windows se instala como cualquier otro software y en Linux corre bajo un navegador web. Vamos a verlo funcionar en Linux. Es un Framework muy intuitivo.
En lo personal, diré que prefiero usar TSK en su modo terminal en lugar de en su entorno gráfico a través de Autopsy, pero hay que conocer todos los modos de trabajo.
Hay varias formas de instalar Autopsy, pero vamos a hacerlo fácil, muy fácil.
sudo apt-get install autopsy
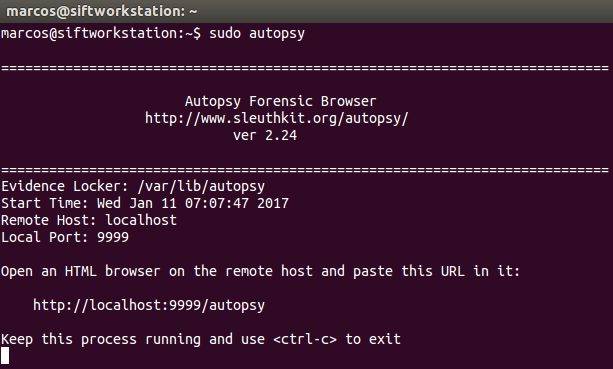
Tras su instalación, levantamos un terminal y tipeamos
sudo autopsy
Esta ventana de terminal debemos dejarla activa, abierta. En ella se nos muestra la ruta donde se guardarán los logs; el día y hora de ejecución; y la dirección y puerto sobre el que trabajará, (por defecto en localhost:9999). En esta ventana también se reflejarán los errores que se produzcan, (si es que se producen), y esto nos ayudará a solventarlos.
Así pues, copiamos la ruta http://localhost:9999/autopsy en el navegador que elijamos y accedemos a ella. Si tenemos activado JavaScript nos recomendará que lo deshabilitemos.
Una vez en la pantalla principal de Autopsy, clicamos en ‘New Case’ para proceder a generar el caso.
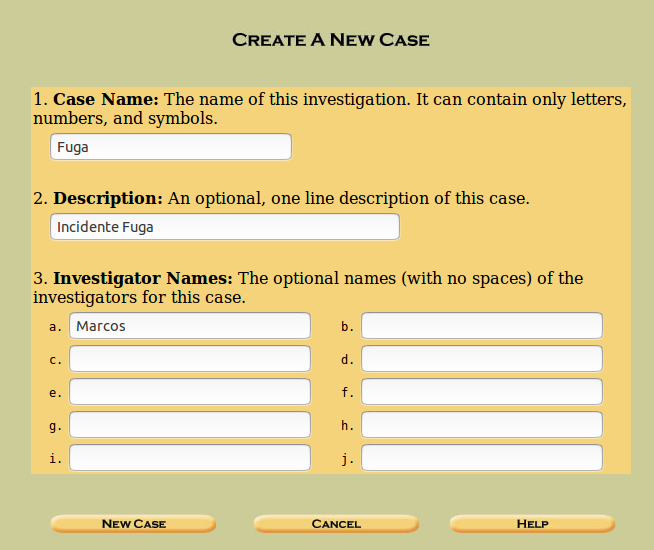
Rellenamos los datos relativos ‘Case Name’, que es un nombre de directorio válido, (sin espacios y sin símbolos), ‘ Description’ e ‘Investigator Names’ y clicamos en ‘New Case’.
La siguiente pantalla que se presenta nos informa de que se ha creado el caso, en la ruta ‘/var/lib/autopsy/*****/.
Se nos pide que creemos un host y que especifiquemos un analista.
Clicamos en ‘Add Host’.
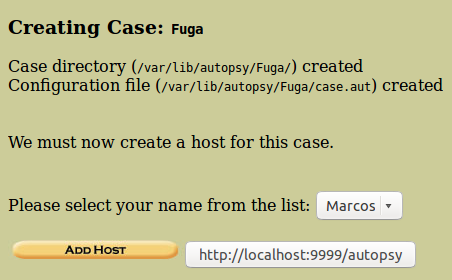
En este punto, se nos presenta nuestro caso, donde debemos especificar el nombre del host; una pequeña descripción; la zona horaria, (por defecto es la local de nuestro laboratorio).
Clicamos en ‘Add Host’.
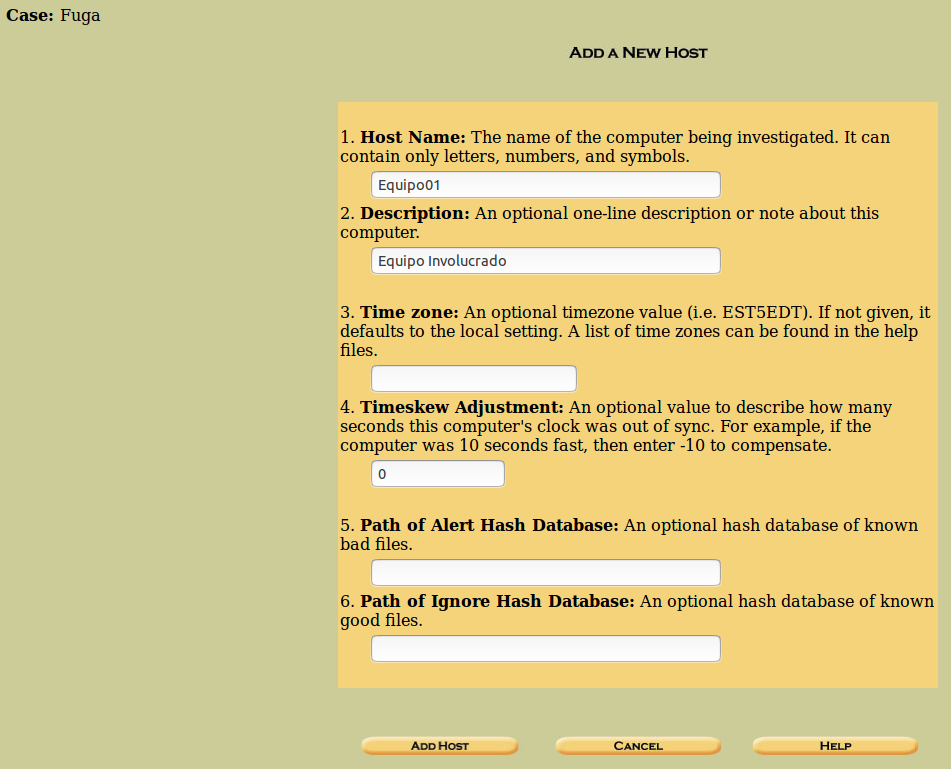
Ahora se nos informa que se ha añadido el host que le hemos especificado, dentro de la ruta anterior. También nos dice que debemos importar un fichero de imagen. Es decir, al añadir un host, se crea una carpeta dentro del directorio del caso.
Un caso puede contener uno o más host. En caso de que queramos agregar más, debemos ir ‘Atrás’ y proceder de igual forma.
Clicamos en ‘Add Image’.
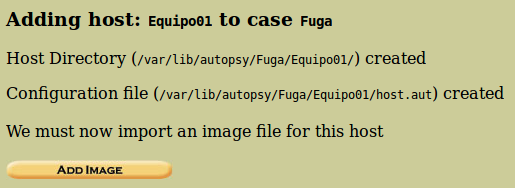
En esta pantalla debemos clicar en ‘Add Image File’.
Ahora se nos presenta la pantalla donde agregaremos el fichero de imagen del disco.
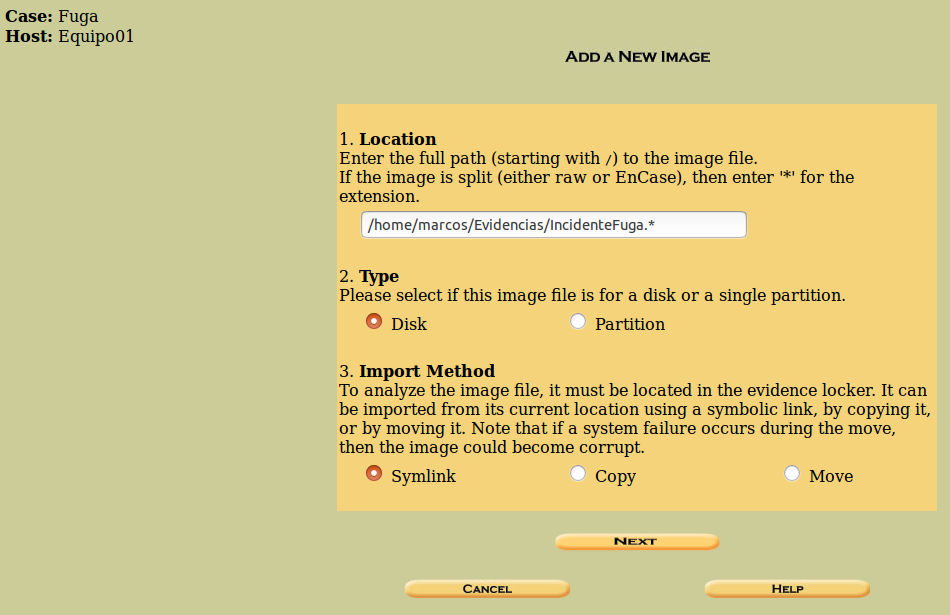
Especificamos la ruta donde se encuentra alojada la Evidencia. Si es un único fichero de imagen, se puede especificar sin más. Y si nos encontramos con una imagen fraccionada en varios ficheros, podemos usar el parámetro ‘.*’ en lugar de la extensión. Esto nos ahorrará el paso de juntar previamente los ficheros.
Elegimos el tipo de imagen, si se trata de un disco o de una partición.
Y elegiremos el método de importación de la imagen. Crear un vínculo simbólico, copiar el fichero de imagen o mover el fichero de imagen.
Por último, clicamos en ‘Next’.
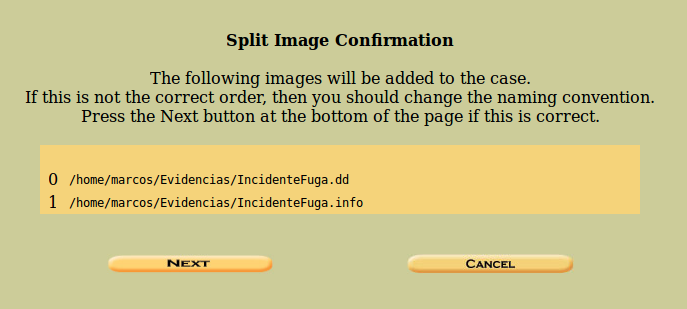
Como acabamos de mencionar, si usamos el parámetro ‘.*’, se nos mostrará la información relativa a esos ficheros, que procederá a juntar. En este caso tan solo hay un fichero.
Clicamos en ‘Next.
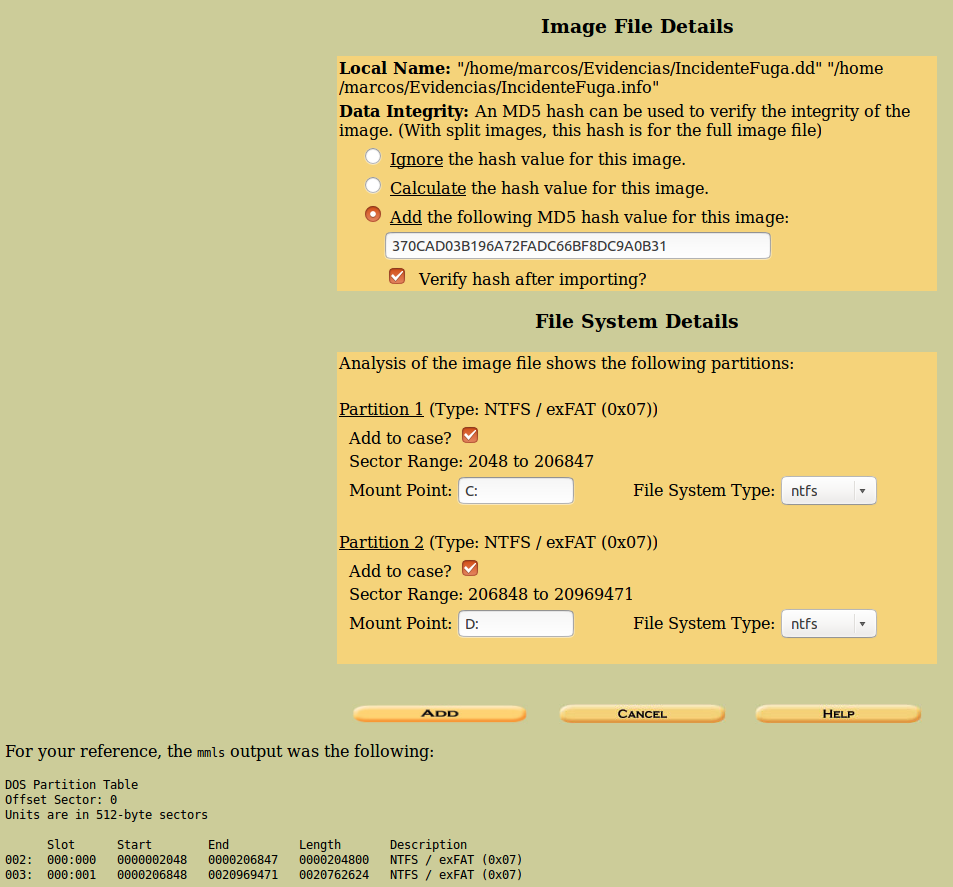
En la siguiente pantalla, se nos presentan los detalles de la imagen, (la ruta donde se encuentra alojada). Debemos añadir el valor de su algoritmo MD5 y marcar la casilla de ‘Verify hash after importing’, porque debemos comprobar el hash que se nos ha entregado con el que vamos a calcular.
También se nos presenta la información relativa al sistema de ficheros, donde se nos mostrará, por defecto, el tipo que usa y nos dará opción a elegir sobre qué partición queremos trabajar.
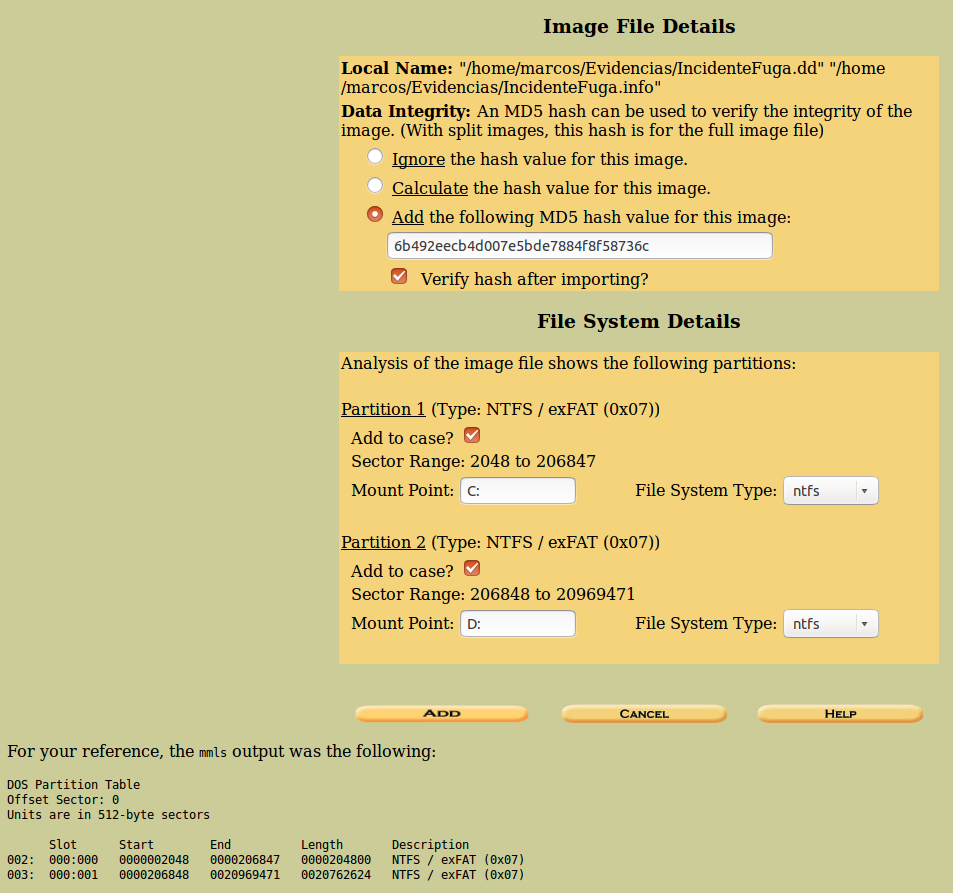
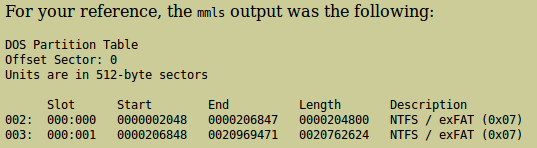
En la parte inferior de la ventana se nos presentará la información relativa al tamaño de los sectores, donde termina y empiezar cada partición y el tamaño de la misma.
Clicamos en ‘Add’.
Puede que nos presente esta pantalla, donde nos informa que la integridad hash del fichero de imagen ha fallado, y que dicha imagen no será añadida al caso.
Bajo mi humilde punto de vista, esto es un error. Porque, aunque no coincida la firma digital de la Evidencia, debemos proceder a su análisis, haciendo constar la incidencia tanto en la hoja de la cadena de custodia como en el informe pericial correspondiente.
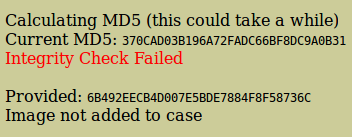
Volvemos atrás. Volvemos a indicarle un valor hash en MD5 y le decimos, nuevamente, que lo verifique.
Clicamos en ‘Add’.
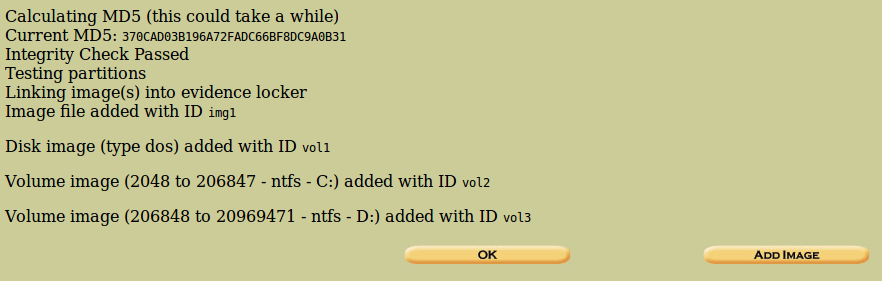
Ahora, si coincide el algoritmo hash proporcionado, nos lo indicará, mostrándonos que la integridad ha sido correcta y que se han añadido las particiones correspondientes.
Clicamos en ‘OK’.
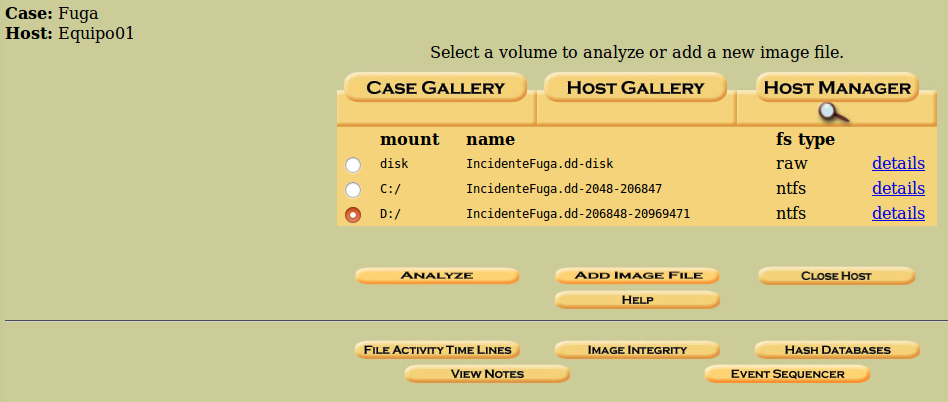
Ahora se nos presenta una ventana, que es la que utilizaremos para seleccionar la partición a analizar.
Igual que en el caso de los host, un host puede albergar uno o más ficheros de imagen. Si queremos añadir más imágenes debemos clicar en ‘Add Image File’ y proceder de igual forma.
Pero antes, clicaremos en ‘details’ de la partición correspondiente.
Como podemos ver, aún no se han extraído las strings de la imagen. Tenemos que generar los índices correspondientes. Para ello, vamos a extraer las cadenas de texto.
Clicamos en ‘Extract Strings’.

Ahora comienza el proceso de extracción de la partición que le hallamos indicado.
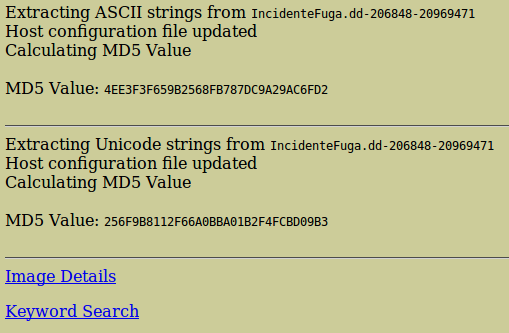
Cuando termine, nos dará opción a volver a ‘Image details’, que será lo que hagamos para seguir extrayendo datos.
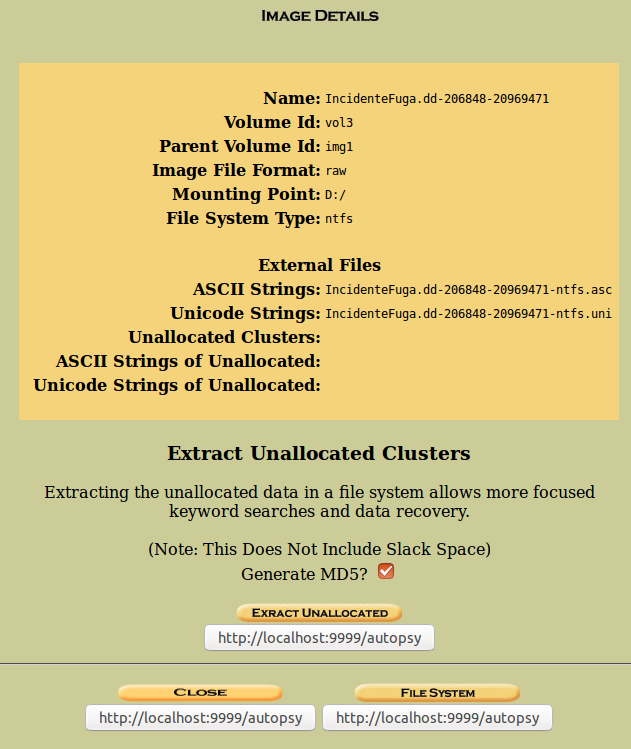
Ahora extraemos la información relativa a los datos que están sin localizar.

Cuando termine, volvemos de nuevo a ‘Image Details’ para seguir extrayendo las cadenas de texto, clicando en ‘Extract Strings’.

Se extraen las cadenas de texto correspondientes.
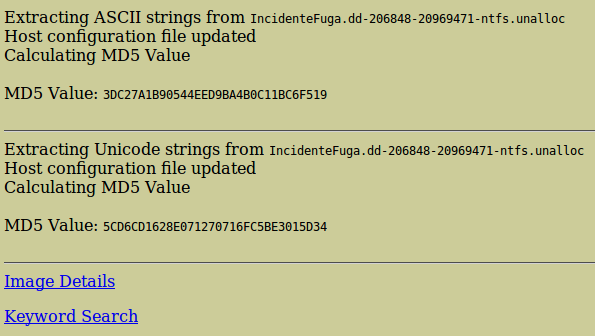
Y cuando termine, si volvemos a ‘Image details’, veremos que ya se han extraído todas las cadenas de texto. Ya se han generado los índices correspondientes.
Si ahora cerramos esta ventana, clicando en ‘Close’
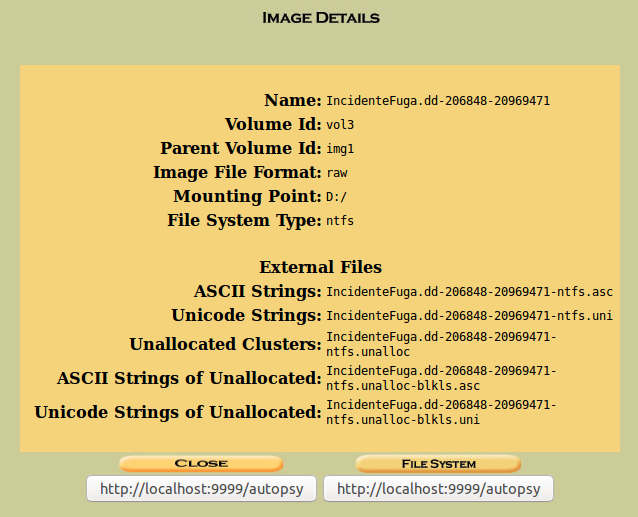
Nos devuelve a la pantalla donde seleccionamos la partición a analizar.
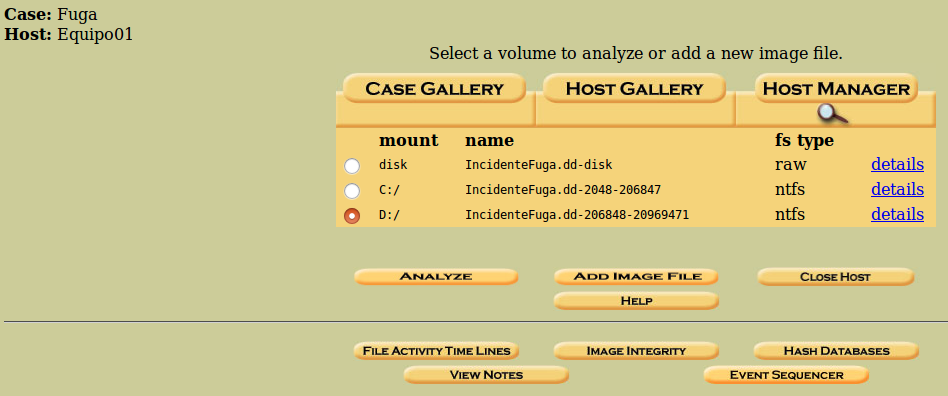
Si seleccionamos la partición y nos dirigimos a ‘Analyze’

Se nos presentan varias opciones.
En este caso, nos dirigimos a ‘Keyword Search’.
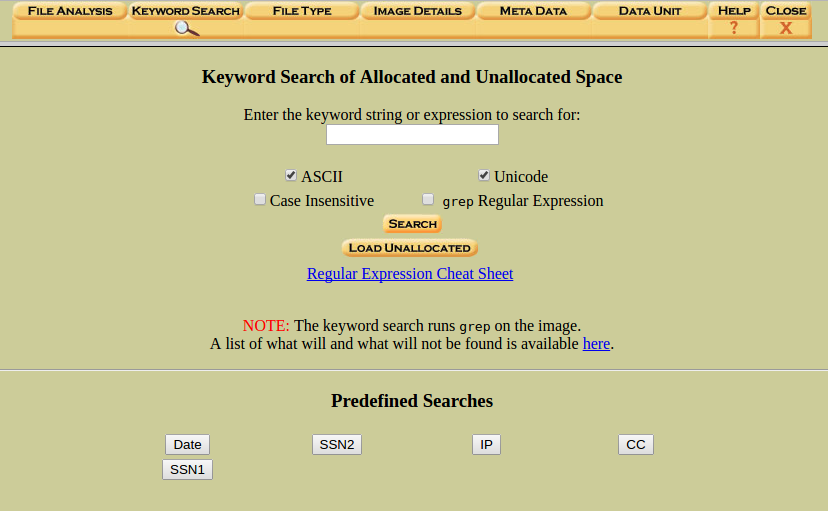
Ahora tenemos varias opciones para realizar búsquedas.
Por un lado, tenemos las búsquedas predefinidas. Podemos usar expresiones regulares, al estilo ‘grep’. Podemos realizar búsquedas sensibles a mayúsculas o minúsculas. Realizar búsquedas en ASCII o en Unicode, (mucho más común en sistemas Windows que en sistemas Unix). Podemos elegir entre ‘Load Unallocated’ y ‘Load Original’, si hemos creado los dos tipos de índices, (No trabajan de igual forma).
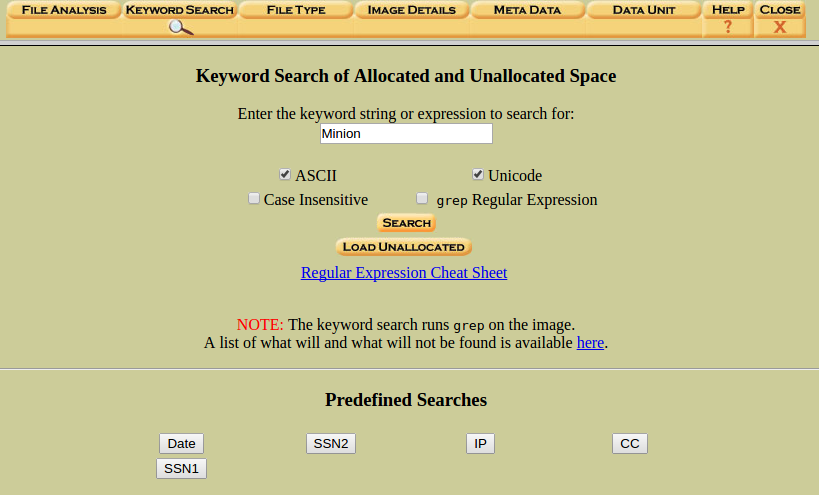
Para este ejemplo, vamos a realizar, primero, una búsqueda normal de texto, marcando ASCII y Unicode.
Clicamos en ‘Search’.
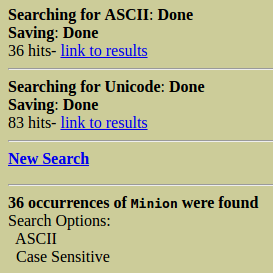
Cuando termine la búsqueda, se nos mostrarán los resultados en el lado izquierdo de la pantalla, separando los mismos entre ASCII y Unicode, con sus correspondientes links a los espacios de cada resultado.
En este caso nos devuelve 36 coincidencias para ASCII y 83 para Unicode.
Si seleccionamos un resultado en ASCII obtendremos esta vista, con esta información. Podemos ver la información mostrada, tanto en ASCII, como en Hex

Y en ASCII Strings. Podemos generar un reporte de esta información. También podemos ir a la dirección asignada en ‘Meta Data Address’.
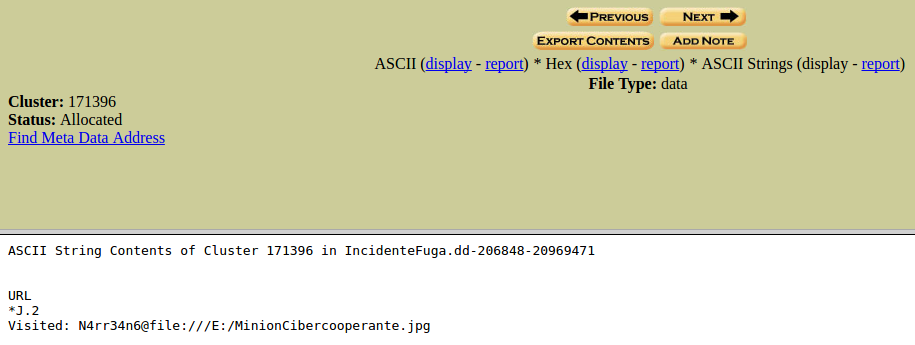
Ahora vamos a ver los resultados Unicode.

Si seleccionamos uno de ellos se nos presenta esta información.
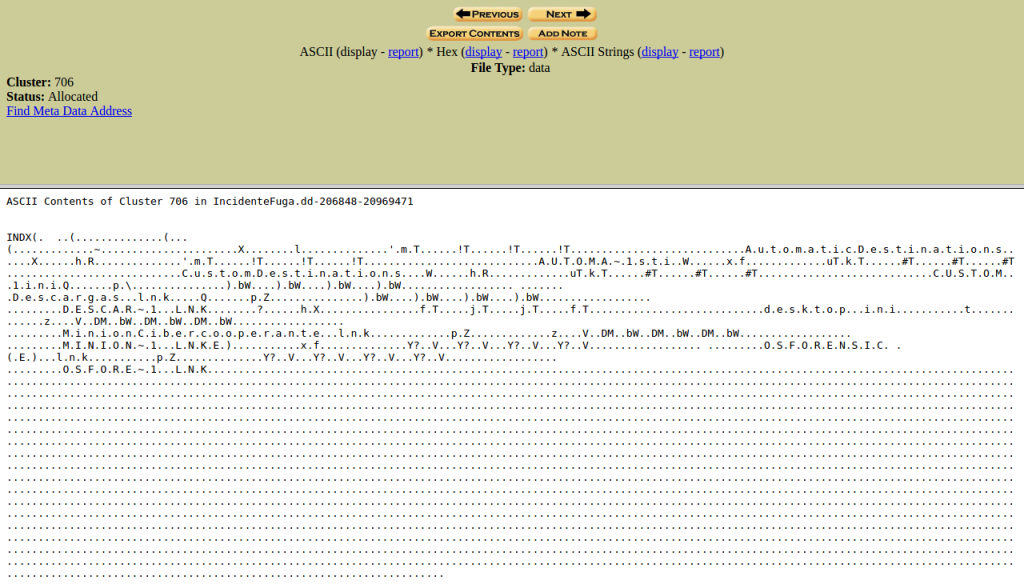
Que podemos manejar de la misma forma que la anterior. Eligiendo entre ASCII, Hex y ASCII Strings.
Fijaros en qué resultados se obtienen.

Ahora vamos a realizar una búsqueda en el espacio sin asignar, de la misma forma que antes.
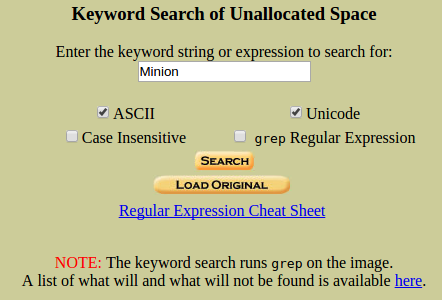
Igualmente, se nos separa los resultados de ASCII y Unicode.
En este caso nos devuelve 3 coincidencias para ASCII y 19 para Unicode.
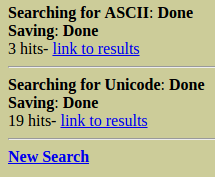
Si seleccionamos uno de ellos obtenemos esta información que se puede ver.
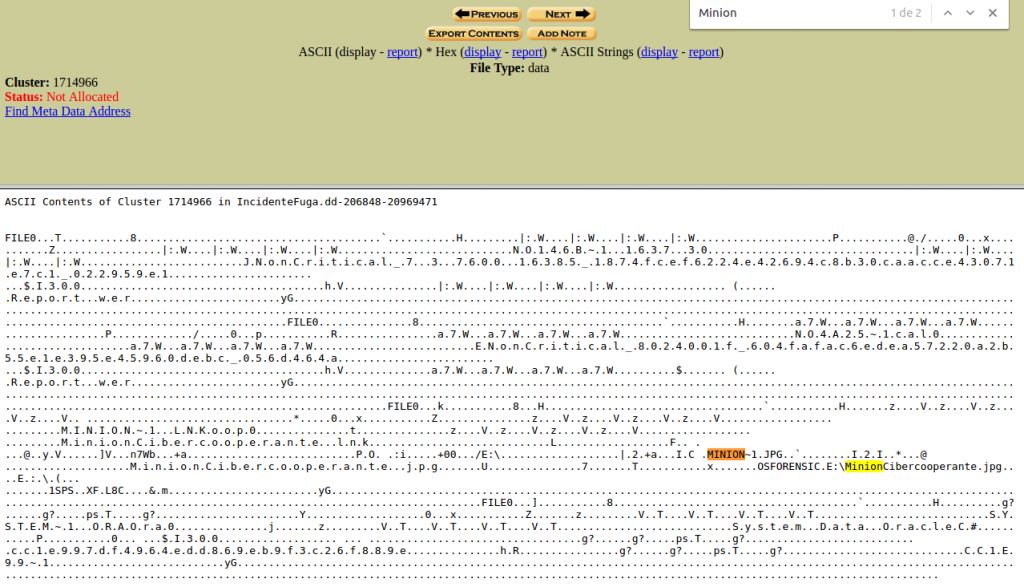
Y también podemos ver los resultados en ASCII, Hex y ASCII Strings. Podemos generar un reporte y podemos ir a su dirección correspondiente.
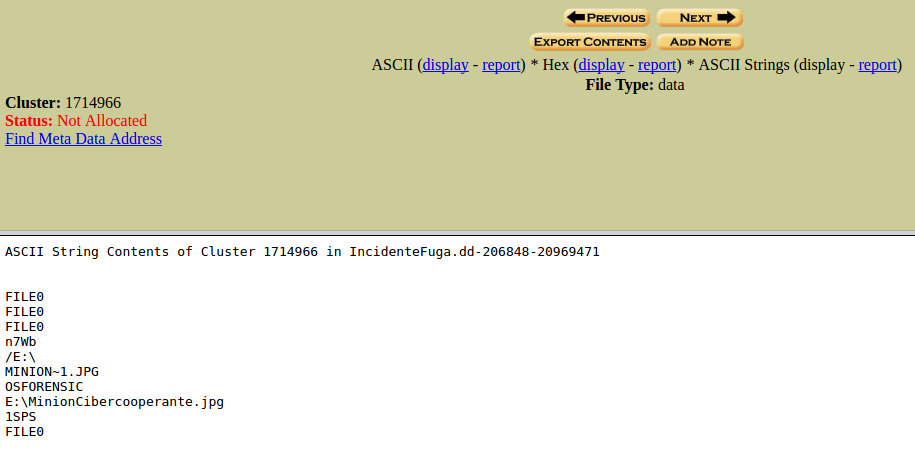
Si nos dirigimos a un link Unicode

Vemos lo que tenemos de igual forma.
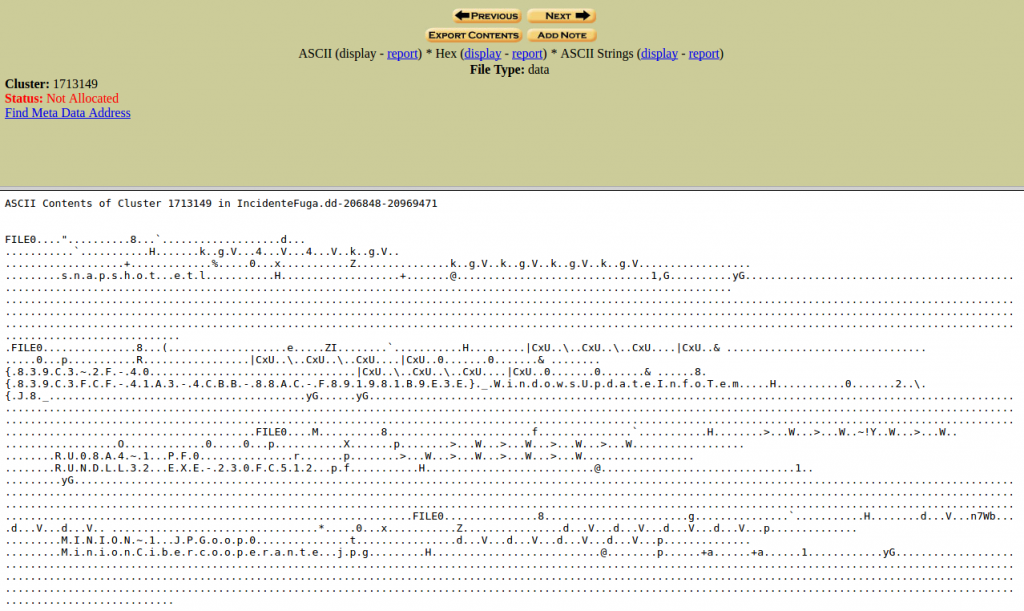
Y de igual forma podemos ver sus resultados, entre ASCII, Hex y ASCII Strings.
Fijaros en qué resultados se obtienen y compararlos con el anterior.

Daros cuenta que no hemos obtenido la misma cantidad de información usando un tipo de búsqueda que otro. Difieren.
Todos los resultados de las búsquedas que hagamos se guardarán en un fichero, por lo que no será necesario realizar una misma búsqueda.
También esta Suite nos genera un fichero log del caso, que podemos consultar mediante
cat /var/lib/autopsy/Fuga/case.log
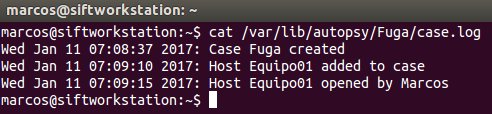
Ahora, comparad esta forma de trabajar con la que vimos en la entrada anterior.
No voy a entrar en las diferencias de cada Suite. Eso el algo que os dejo a vosotros. Probadlo. Trastead. Curiosead.
Esto es todo, por ahora. Nos leemos en la siguiente entrada. Se despide este minion, entregado y leal, de vosotros… por ahora.
Marcos @_N4rr34n6_