
Buenas!!!
El pasado día 24 de Febrero, tuve el placer de participar como ponente en la Hack&Beers de Madrid Vol.8 en la que impartí la charla «RastLeak: Leak Information as a Service» .
Además, me gustaría dar las gracias a la organización de la Hack&Beers, así como a los organizadores de la misma en Madrid: Valentín y Miguel por darme la oportunidad de dar esta charla permitiéndome mostrar mi investigación 😉

La ponencia la enfoqué en cómo emplear la técnica del Hacking con Buscadores para obtener información indexada en los principales buscadores y explicar cómo a través de la misma se puede utilizar en un proceso de pentesting web. Además, también indiqué como empleando está técnica se puede identificar ciberfraude basado en phishing, typosquating y abuso de marca. Finalmente, presenté la herramienta RastLeak que he desarrollado para automatizar búsquedas manuales.

A nivel personal, ha sido un subidon desarrollar esta herramienta tras las investigaciones que llevo realizando desde hace un par de meses desde que me surgió una necesidad que ninguna herramienta del mercado (que conozca) podía ayudarme, por lo decidí profundizar en el tema y directamente desarrollar una, otorgándole un valor añadido respecto a otra herramienta del mercado con un funcionalidad similar.
En esta ocasión, no voy a explicar todo lo que vimos, pues he subido la presentación y podéis acceder a ella aquí . Por lo que espero que os sea útil y en caso de que tengáis alguna duda estaré encantado de ayudaros 😉
No obstante, también se muestran a continuación, para que las podáis visualizar sin salir de la página actual 🙂
Respecto a RastLeak, se trata de una herramienta que automatiza la técnica de hacking con buscadores para buscar documentos ofimáticos (pdf, doc, docx, xls y ppt) de un dominio que se encuentren indexados así como visualizar la ruta en la que se encuentren permitiendo su descargar y extracción de metadatos. Hasta aquí, no es nada nuevo, esto mismo lo hace la FOCA, sin embargo, le he añadido la funcionalidad de buscar documentos ofimáticos que contengan ciertos keywords sobre un target en dominios fuera del alcance de dicho target. Esta funcionalidad es el valor añadido en comparación con la FOCA.
Como demostré su funcionamiento a través de vídeos y como me gustaría optimizar código y añadir alguna funcionalidad más antes de subirla a github, a continuación, muestro un par de capturas para que la gente que no pudo asistir se haga una idea de su funcionamiento 😉
Tras el disclamer, os presento a RastLeak:
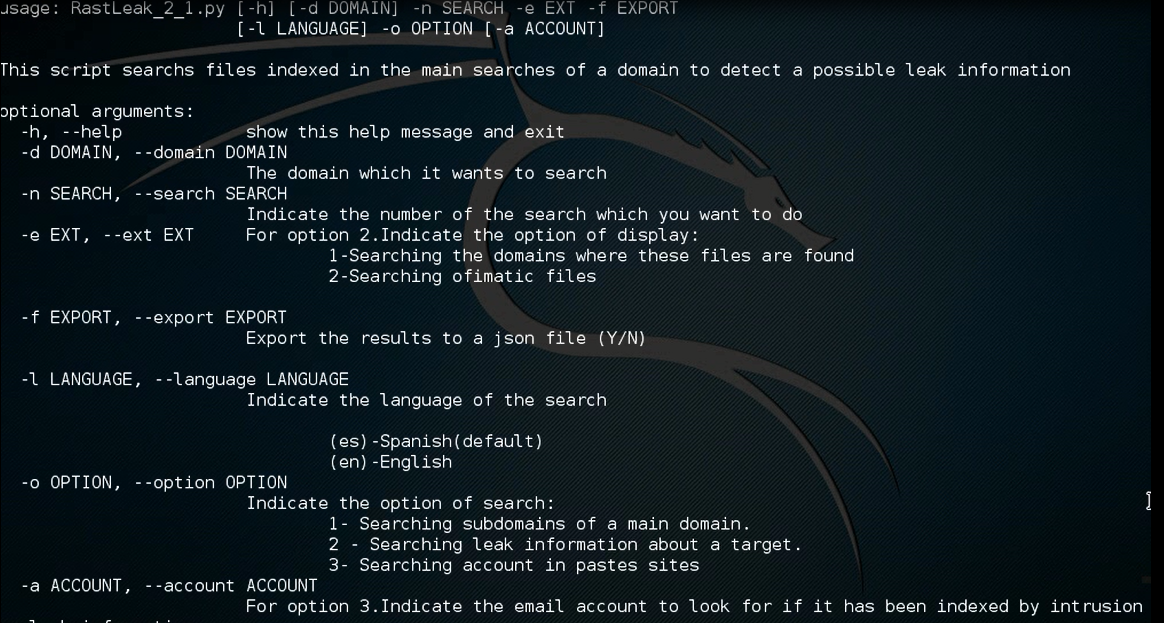
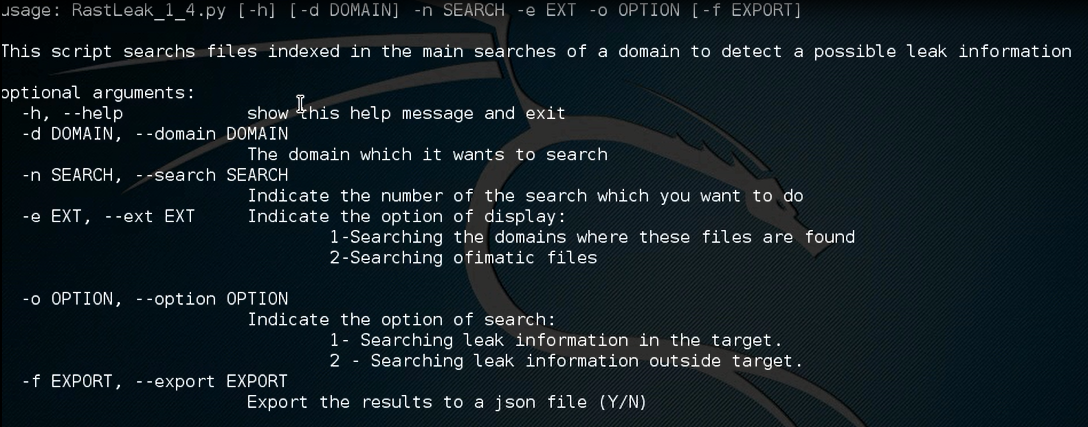
En este punto se pueden ver las diferentes opciones que ofrece la herramienta, destacando que la opción 3 está desarrollado pero me falta por testear, por lo que no pude enseñarla en la Hack&Beers.
Seleccionando la opción 2, se muestra un submenú para buscar fuga de información dentro del target, es decir, en sus dominios, o por el contrario, fuera de ellos. En esta opción se emplea como buscador Google.
A continuación, se muestra la funcionalidad seleccionando la primera opción:
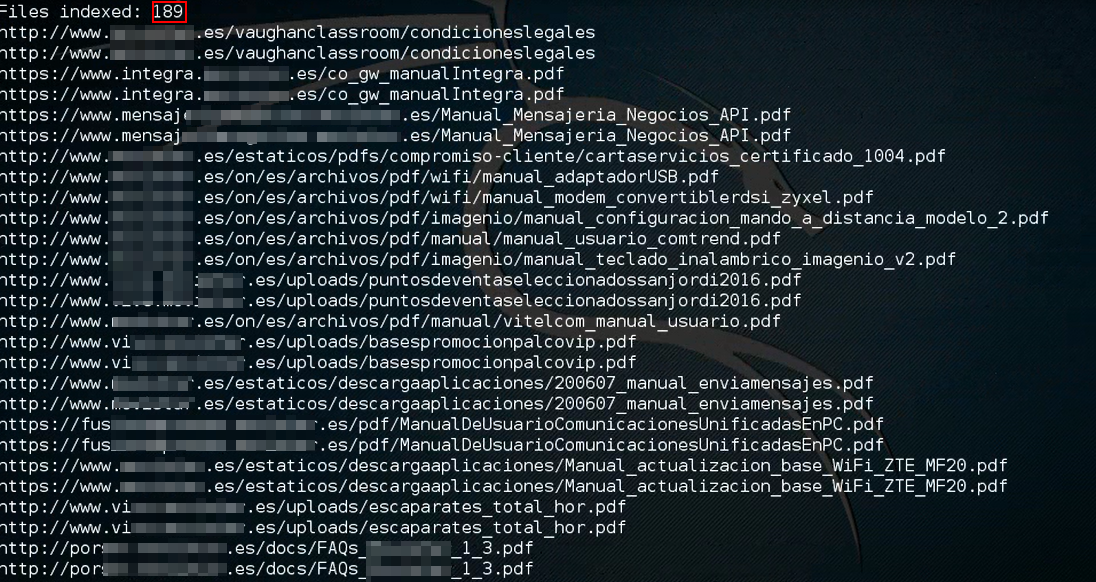
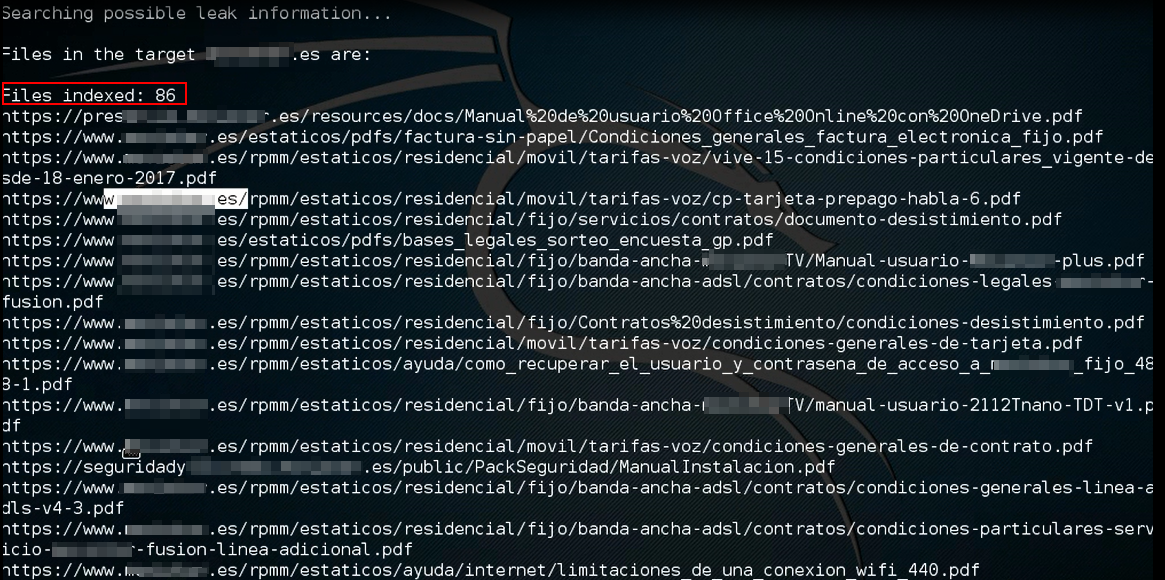
Como se observa, se han localizado 189 documentos ofimáticos en el dominio indicado o bien en sus subdominios. La obtención de mayor número de documentos depende fuertemente del número de resultados indicados a través del parámetro «n», así como la posibilidad de que Google nos pregunte si somos un «bot»

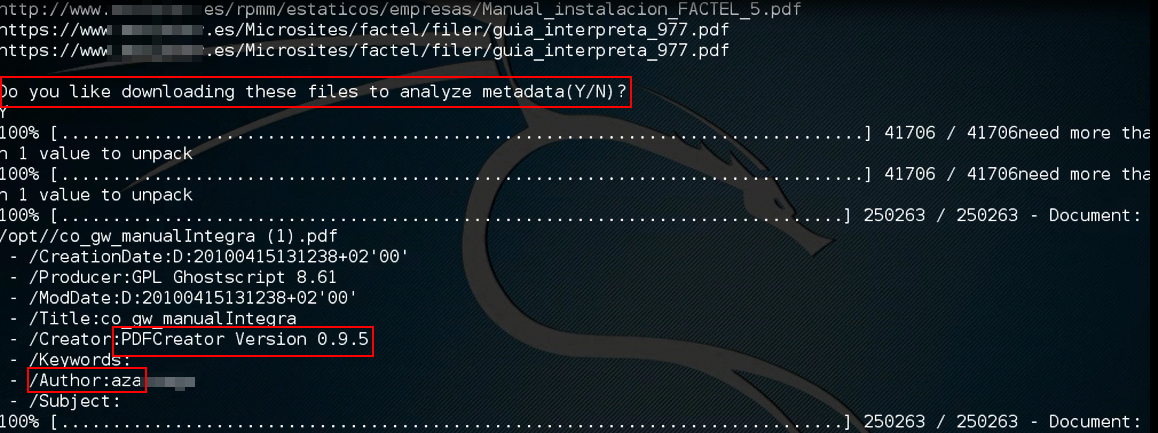
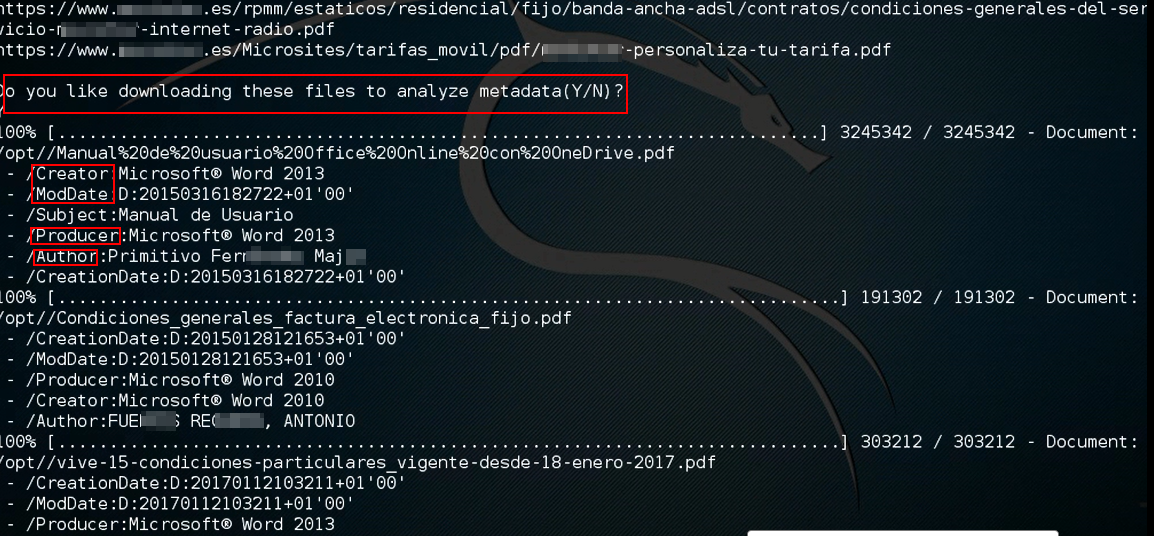
Una vez se muestra la ruta en la que se han localizado los documentos indexados, se pregunta la posibilidad de su descarga y posterior análisis con objeto de extraer metadatos:
En caso de seleccionar la opción 2 del submenú, se buscan documentos que contienen keywords del target pero se encuentran fuera de su infraestructura. En este caso al estar fuera del target y no encontrar nada «malo» analizándolo por encima, elegí como target la universidad en la que estudié:
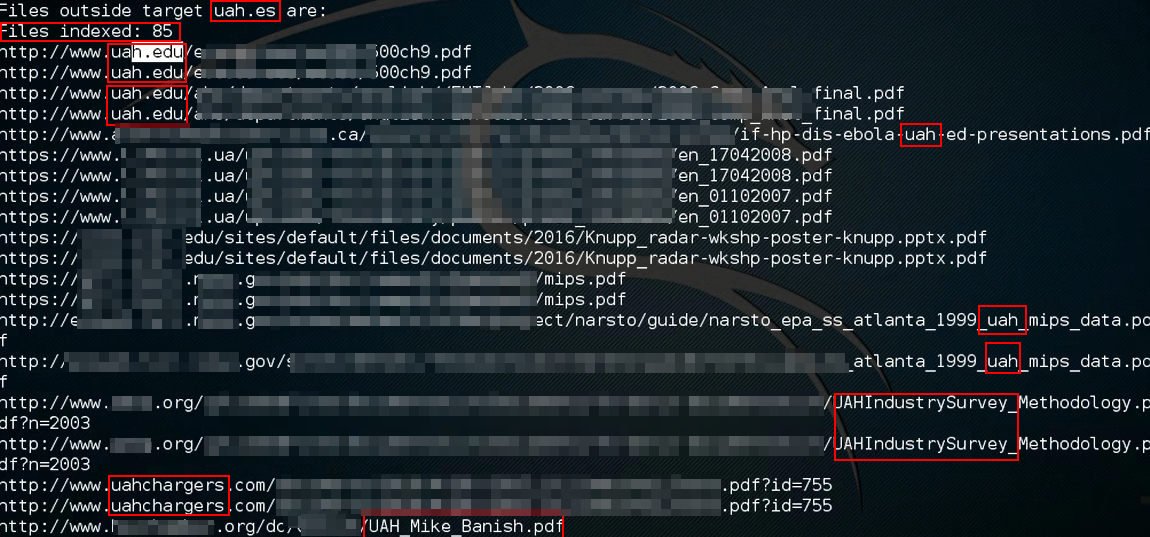
Además, el hecho de visualizar las rutas, nos permite encontrar rutas interesantes como las últimas que se observan que contiene un «id=755», que en el caso de un pentesting web, se podría inyectar código para identificar si posee alguna vulnerabilidad web, ya sea un XSS o un SQL Injection. Del mismo modo, como en la opción 1, se da la posibilidad de descargar estos documentos y extraer sus metadatos.
Finalmente, aunque al principio no estaba previsto, mostré una demo del estado anterior de RasktLeak cuando no podía con Google y empleaba Bing como buscador para «buscar» (valga la redundancia) documentos indexados. Entonces, quiero añadir la posibilidad de que en el caso de Google baneé la IP, emplear esta opción:
En este caso se puede jugar con el parámetro «e» para filtrar los resultados obtenidos, si bien se desea ver la ruta completa del documento ofimático indexado encontrado, o por el contrario, solamente el dominio en el que se encuentra.
A continuación, se muestran ambas opciones:
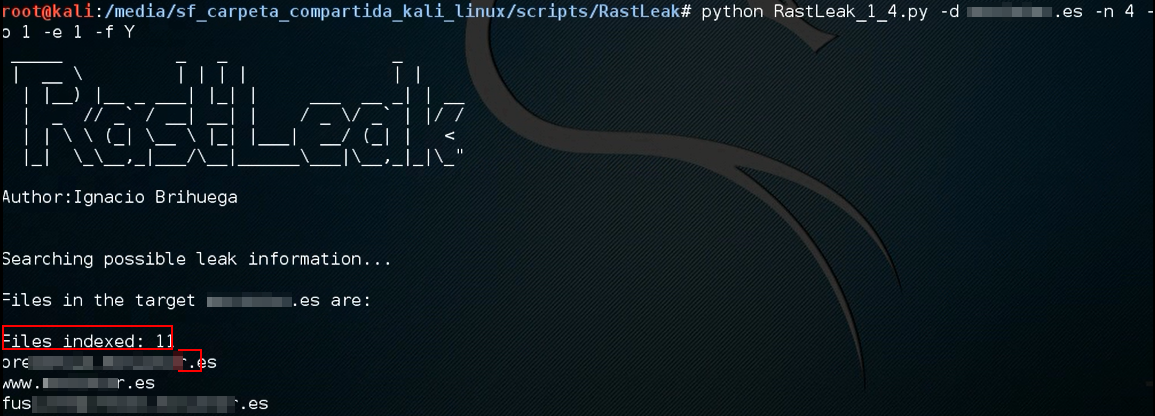
- e=1 => Sólo dominios
- e=2 => Ruta entera
De la misma manera, se da la opción de descargar dichos documentos y extraer sus metadatos:
Como ya me preguntásteis en la Hack&Beers, mi idea es subir la herramienta a github má adelante cuando optimice código y añada algunas funcionalidades que tengo en la cabeza, así os pido paciencia =D
De momento, esto es todo. Espero que disfrutaráis tanto como yo a las personas que pudieron acercarse y a las que no pudieron asistir, espero que este post, os sirva de consuelo 😉
Ante todo, espero que os haya sido útil y recordar: «Un gran poder, conlleva una gran responsabilidad», usemos estas técnicas con fines académicos.
Saludos.
N4xh4ck5
«La mejor defensa es un buen ataque»
Un comentario en «Hack&Beers Madrid – Vol 8 – RastLeak»