
Hola a todos!
Volvemos de nuevo por aquí de cara a sacar un par de post’s hilando con el taller «Pentesting a la autenticación biométrica» que impartí recientemente en Euskalhack VIII.
Como siempre es un honor y un placer participar en este evento, así como volver a Donostia y País vasco. Me gustaría dar las gracias a la organización por el esfuerzo y dedicación para montar cada edición (ya son 8!) con objeto de regalar un evento de estas características y con una calidad enorme. Así como a nivel particular por seguir confiando en mí y ser ponente por 5º vez.

Deepfake, clonación de voz y rostro, que si IA por aquí, que si hago un meme con esta app,…pero realmente que oportunidades y peligros está posibilitando el estado actual de la IA.

El taller está enfocado en la clonación de voz y rostro para posteriormente utilizarlo con fines como podrían utilizarlos los malos para impersonalizar a un individuo tal que pudiera usar su identidad digital para dar de alta en un servicio por ejemplo. Asimismo, se montaron sistemas de autenticación empleando modelos pre-entrenados para verificar si las muestras de voz y rostro son reales o FAKE, así como si pertenecen a la misma persona.
El taller se estructura de la siguiente manera:
- Voz
- Clonación de voz: Tecnología TTS y STS.
- Autenticación contra asistentes de voz (Alexa y SIRI)
- Desarrollo agente basado en IA.
- Modelos utilizados actualmente
- Creación sistema propio de autenticación.
- Testeo del sistema
- Rostro
- Herramientas Deepfake en tiempo real y pre-grabadas.
- Lecciones aprendidas y consejos en el desarrollo de deepfakes
- Validación de deepfakes online.
- Desarrollo de sistemas propios usando modelos con kaggle y colab.
En primer lugar, se comienza con la suplantación de la huella vocal haciendo especial hincapié con la diferencia de la tecnología TTS (Text-To-Speech) y STS (Speech-To-Speech) a la hora de conseguir resultados y especialmente aclarando que la primera se basa en una síntesis de la voz mientras en la segunda sí se basa en una clonación real, esto es, ritmo, timbre, estrés, estilo,…

¿De donde se saca la voz que se desea clonar?
- Clonar la voz de un fichero multimedia obtenido de RRSS: Twitter (X), Youtube u otras.
- Clonar la voz de una persona mediante una simple muestra de N segundos.
- Clonar la voz de un audio de aplicaciones de mensajería como WhatsApp o Telegram.
Seguramente la tercera opción es la que te ha venido querido lector de este post, sí justo del amigo que te imaginas que siempre te hace audios de unos segundos hasta capítulos de un podcast xd

Para realizar la clonación se puede hacer localmente usando pinokio + applio + modelos pre-entrenados o incluso montarte uno propio o bien, empleando plataformas online como Elevenlabs o Minimax. Si quieres conocer más como hacerlo con Elevenlabs, te dejo este post que escribí por evitar repetirlo en este 😉
Si se toma la opción de hacer una PoC con un vídeo de Youtube en el que puede hacer música de fondo, recomiendo usar la opción de aislar la voz de cara a sacar una clonación de calidad.
Respecto a los asistentes de voz, Alexa mediante echo Dot no implementa un sistema de autenticación como tal sino que si le preguntas «¿Quién soy? te indica si es capaz de reconocer tu voz. Para este caso, aunque la clonación sea TTS y con una muestra de baja calidad te reconoce la voz.

En el caso de SIRI sí es más interesante pues requiere una clonación real (STS) para que accede a tu petición vía voz.

Seguidamente, se explica el uso de los agentes de bot que dispone Elevenlabs y el uso que se le podría dar para realizar desde una campaña de vishing. Desde la última que lo revise (allá por marzo 2025 para RootedCon) ya existía la integración con Twilio pero no lo vi claro. Ahora han añadido nuevas integraciones y herramientas, por lo que lo añadiré a mi lista de TO-DO:
A continuación, se entra en el uso de los modelos X-Vector y ECAPA-TDN para reconocer voces sintéticas. Se desarrolla un sistema de autenticación haciendo uso de colab (aquí los scripts) tal que se introducen muestras de voz (al menos 2) en la que se le indica al sistema cual es la voz real para que así se puede comparar con las clonadas. El sistema indica si la voz es REAL o FAKE y si pertenece a la misma persona.

En los siguientes posts entraremos en más detalle 😉
Pasando a la clonación de la huella facial, se comenta el estado actual centrado a nivel empresarial, más allá de las apps utilizadas para hacer memes. En este punto, se comenta como las empresas están pidiendo nuestros rasgos biométricos para darse de alta en un servicio o incluso abrir una cuenta bancaria. Para ello, se está pidiendo desde un selfie, escanear el DNI o pasaporte o incluso una prueba de vida mediante un vídeo con movimientos para así detectar si se ha utilizado deepfakes.

En este escenario se está pasando desde plugins en el navegador, URL o iframe a ser mandatorio realizar desde la app móvil desde un dispositivo físico. Aquí ya se entraría en inyectar un vídeo pre-grabado mediante un ataque de MiTM o hasta hookear los proceso para pasarle a la app la cámara digital en lugar de la nativa del teléfono móvil.
Tanto en la clonación de voz como en rostro, pero más si cabe en la clonación de huella vocal la capacidad de procesamiento ya sea tirando de GPU como de tarjeta gráfica se convierte en algo fundamental.
Desde tools de deepfake en tiempo real como iRoopDeepFaceCam y Deep-Live-Cam o hasta pre-grabadas DeepFaceLab y FaceFusion. En próximos posts, se verán sus ventajas e inconvenientes así cuál puede ser más útil según el contexto.
Seguidamente, tras disponer de muestras clonadas de vídeo e imagen llega la hora de comprobar cómo de buenas (o malas) son frente a diferentes herramientas como chatGPT o DeepWare

Ahora haciendo uso de kaggle, se van a crear varios notebooks (los podéis encontrar aquí) donde se cargarán diferentes modelos pre-entrenados para hacer la detección de imágenes y vídeos.

En el caso de la detección de vídeo se extrae cada fotograma y se añade el resultado según el frame:
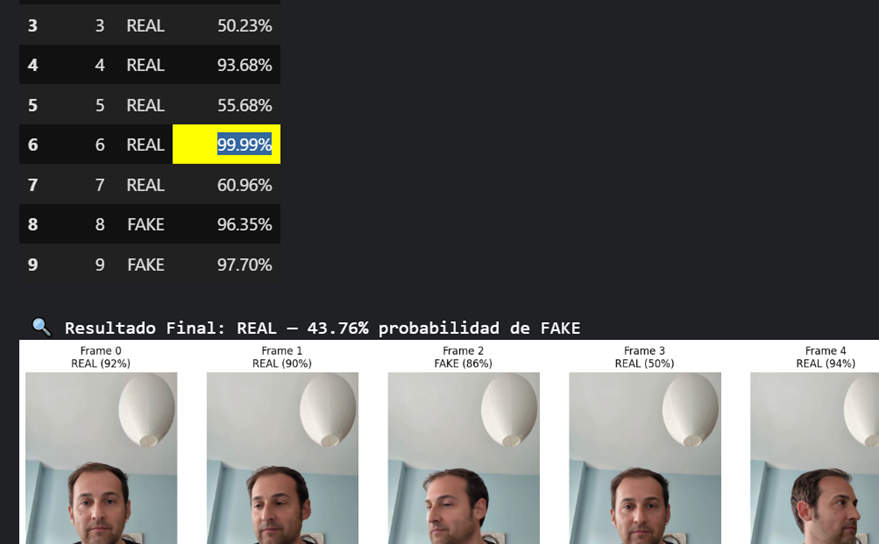
Así se puede detectar en qué parte es más robusto o en cuál flojea más la clonación hecha. Además, muy vital saber cómo de buenos son los modelos utilizadas para la detección.
Este post, es un resumen de lo que se vieron en las 2 horas del taller en Euskalhack que entraré en detalle en los siguientes post’s.
La slides que use las podéis encontrar en mi github.
El objetivo del post es dar una referencia o apoyo para iniciarse en el pentest de sistemas de autenticación basados en biometría, así como una manera para mejorar la prevención y respuesta. Ni el autor ni el blog se hacen responsable de su uso para otros fines diferentes a la formación.
Nos vemos en el siguiente post!
Saludos.
N4xh4ck5
La mejor defensa es un buen ataque