Hola a todos!
Continuamos con otro post’s en relación al taller «Pentesting a la autenticación biométrica» que impartí en la pasada Euskalhack que podéis revisar aquí.
En este post’s continuamos con los ataques a la huella vocal. Antes de continuar te recomiendo que revises el post’s anterior así como éste, puesto que se explica como se realiza la clonación de voz que es el input que usaremos para testear modelos de reconocimiento empleados en sistemas de autenticación basados en la huella vocal.
Se parte de varias clonaciones realizadas usando tanto la tecnología TTS (Text To Speech) como STS (Speech to Speech) así como el ajuste de similitud, estilo y estabilidad. Es importante recordar que no vale la misma configuración para todas las voces, así como la diferencia entre la síntesis de TTS frente la clonación de STS.
A continuación, se utiliza Google Collab como plataforma en cloud para ejecutar una serie de scripts en lo que se van a emplear diferentes modelos de reconocimiento de voz. Estos scripts los podéis encontrar aquí:
Seguidamente se explica el funcionamiento de los scripts:
- Se pide la subida de al menos dos voces (una real y otra clonada).
- El formato esperado es .wav
- Si el formato es diferente el propio script realizará una conversión. Esta conversión puede afectar a la calidad del audio.
- Se debe seleccionar cuál es la voz real para así comparar con el resto de voces.
- El resultado indicará si la voz pertenece a la misma persona así como un umbral que según su resultado indicará el grado de similitud si es muy bajo, bajo, medio, alto o muy alto.
Una vez, explicada la teoría, se procede a la práctica 😀
Comparador de voz X-Vector.
Utiliza el modelo X-vector entrenado con VoxCeleb. A continuación, se deja referencia sobre el modelo:
https://huggingface.co/speechbrain/spkrec-xvect-voxceleb
https://speechbrain.readthedocs.io/en/latest/API/speechbrain.lobes.models.Xvector.html
Sus principales características son:
- Ya se ha quedado algo más desactualizado, entre 2017-2018
- Basado en redes neuronales **TDNN** (Time Delay Neural Network).
- Extrae características a nivel de marco.
- Usa capas estadísticas para resumir la información a nivel de segmento.
Script github: https://github.com/n4xh4ck5/Pentesting_AuthBiometrics_Voice/blob/main/comparador_voces_xvector.ipynb
Ejecutándolo se va solicitar la subida de los ficheros comentados:
Comparador de voz ECAPA.
Utiliza el modelo SpeechBrain para el reconocimiento de voz. Podéis encontrar más info sobre el modelo:
- HuggingFace: https://huggingface.co/speechbrain
- Website: https://speechbrain.github.io/
Sus principales características son:
- Del 2020.
- Añade mecanismos de atención para enfocarse en aspectos relevantes de la voz.
- Usa bloques **Res2Net** y **SE (Squeeze-and-Excitation)** para modelar mejor la variabilidad
- Mayor precisión en verificación y clasificación.
Script github: https://github.com/n4xh4ck5/Pentesting_AuthBiometrics_Voice/blob/main/Comparador_voz_ECAPA.ipynb?short_path=3c508dd
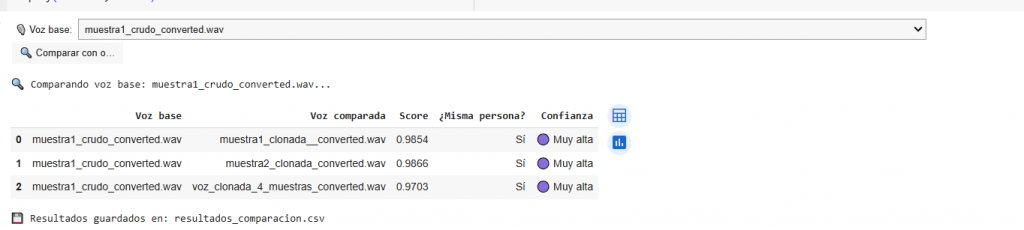
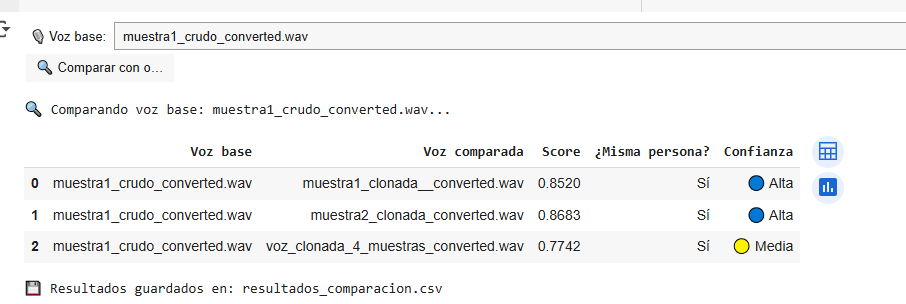
Tras la subida e indicar con qué se va a comparar, el resultado sería:
Subiendo otras muestras:
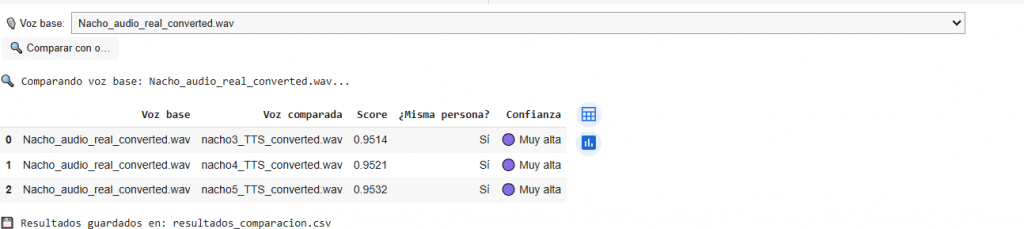
Tras la subida e indicar con qué se va a comparar, el resultado sería:
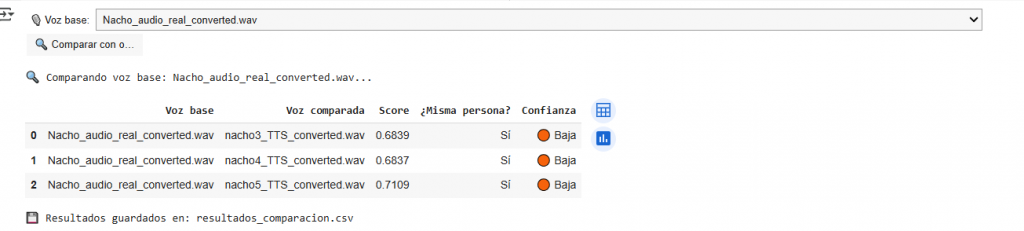
Subiendo otras muestras:
Como se observa con las mismas muestras en el primer script usando el modelo X-Vector el resultado tiene un score muy alto, mientras con el modelo ECAPA, hay una gran diferencia. Las características incorporadas en ECAPA para detectar aspectos relevantes y en función del uso de la tecnología TTS o STS son los responsables del comentado score.
Finalmente, se ha creado un script para juntar ambos modelos y llevar a cabo la comparación:
Script github: https://github.com/n4xh4ck5/Pentesting_AuthBiometrics_Voice/blob/main/Comparador_Voces_Modelo_x_vector_ECAPA.ipynb
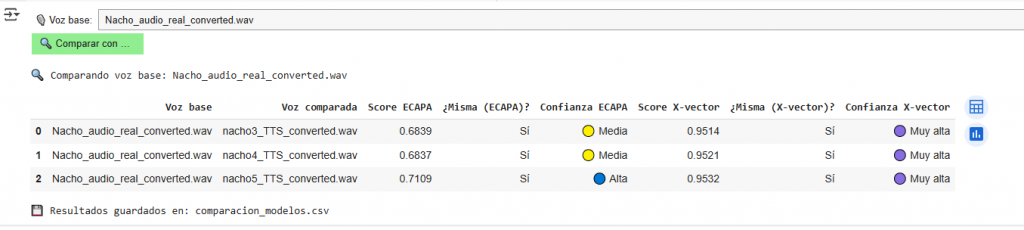
Para la segunda tanda de muestras:

Las muestras utilizadas han sido clonadas haciendo uso de ElevenLabs.
Todos los scripts se pueden encontrar en este repo de mi github.
Igualmente si quieres profundizar sobre esta temática nos veremos en la Secadmin de este año donde impartiré la segunda versión del taller.
Espero que os haya sido de utilidad e interés 🙂
Nos vemos en el próximo post
El autor ni el blog se hace responsable de su uso para otros fines diferentes a la formación.
Nos vemos en el siguiente post!
Saludos.
N4xh4ck5
La mejor defensa es un buen ataque